고정 헤더 영역
상세 컨텐츠
본문
Improving Language Understanding by Generative Pre-Training (GPT) 논문 리뷰
Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다
Abstract

- Natural Language Understanding 을 위한 모델로, Unlabeled Dataset 을 활용할 수 있는 GPT를 제안한다
- 아래의 두가지 방법을 결합함으로써 Unlabeled Dataset 을 활용하여 더 좋은 모델(GPT)을 얻는 것이 가능하다
- Generative pre-training : Language Model 방식으로 Unlabeled text data 를 학습
- Discriminative fin-tuning : 각 Downstream task 에 따라 fine-tuning 을 진행
- GPT는 fine-tuning 과정에서 모델 구조상의 최소한의 변형만 필요로 한다 (Add Linear Layer)
- Pre-training을 통해 일반화를 시도한 GPT는, 각 task 에 맞게 변형되고 discriminative 하게 학습된 모델들보다 우세한 성능을 보였다. 벤치마크 12개 중 9개에서 유의미한 성능 우세를 보였다.
1. Introduction
NLP에서의 Semi-supervised Learning 방식의 접근의 어려움 (Unsupervised + Unlabeled data)
NLP에서 Labeled Dataset 의 양이 비교적 적고, Unlabeled Dataset 은 풍부한 편이다.
새로운 Annotation 은 시간과 비용이 많이 소요되므로, Unlabeled Dataset 으로부터 언어정보를 추출하여 사용한다면 더 나은 선택이 될 수 있다.
Unlabeled Dataset 을 Unsupervised 방식으로 사전학습에 활용했을 때 (Semi-supervised Learning), 더 좋은 representation 을 얻을 수 있다는 것이 선행연구에서 보였기 때문이다.
그러나 이러한 Semi-supervised Learning 방식의 접근에는 2가지 어려움이 있다.
- 사전학습 모델의 목적함수 정의 측면 : Transfer-learning 에 유리한 Pre-train objective 를 정의하는 것의 어려움
- 전이학습 방식 측면 : 효과적인 transfer-learning 방법을 찾는 것의 어려움
GPT : Unsupervised pre-training + supervised fine-tuning
비지도학습 방식의 사전학습과 지도학습 방식의 fine-tuning을 결합하여 GPT에서는 Semi-supervised Learning 방식이 가능하게 되었다. 사전학습을 통해 여러 task에 도움이 될 수 있는 방향으로 universal한 representation 을 얻는 동시에 파라미터 또한 학습할 수 있다.
모델의 구조로는 Transformer 을 사용하였다. Transformer를 사용한 이유는 다양한 task 에서 높은 성능을 보여주었기 때문이다.
GPT의 성능을 평가하기 위해 natural language inference (NLI), question answering (QA), semantic similarity, 그리고 text classification 의 4가지 task 의 데이터셋들을 활용했고, 그 결과 12개 중 9개의 데이터셋 성능평가에서 SOTA를 달성하였다.
2. Related Work
Semi-supervised learning for NLP
선행연구들에서는 사전학습을 통해 얻은 word-embedding 으로 downstream task를 학습한 모델이 성능이 우세함을 보였다. 이들이 word-level 의 정보를 transfer-learning에 활용했다면, GPT에서는 semantic-level 에 해당하는 문맥정보를 학습한 후 transfer 하는데 의의가 있다.
Unsupervised pre-training
학습 모델의 좋은 initialization 을 얻기 위해, Unsupervised pre-training을 활용하는 것은 semi-supervised learning 접근 방식에 속하는 하나의 방식이다. 이러한 접근방식은 선행연구에서도 보여준바 있다. 특히, Language-modeling objective로 사전학습을 진행한 뒤 fine-tuning 을 통해 target task의 지도학습을 진행한 선행연구는 GPT 방식과 매우 유사하다.
그러나 GPT는 Transformer 구조를 활용함으로써, 긴 길이의 언어 정보를 학습하고, 더 넓은 범위의 task에 더 높은 성능을 가짐을 보여주었다. 또한 transfer 시, 구조상의 최소한의 수정만 요구한다.
Auxiliary training objectives
선행연구들에서는 POS tagging, chunking, named entity recognition, and language modeling 에 해당하는 다양한 auxiliary NLP task를 target task objective에 더하여, semantic role labeling 을 향상한 바 있다. 특히 최근 연구에서는, language modeling 을 auxiliary objective로 target task 에 더하는 것이 sequence labeling 의 성능 향상을 이끌어냈다.
GPT도 해당방식을 사용하지만, target task 학습 전 이미 target task 와 관련된 언어정보를 상당히 학습했다는 것에서 차이가 있다. (ablation study 에서 증명)
3. Framework
Large corpus + Language Modeling → Labeled Data + Fine-tuning
3.1 Unsupervised pre-training
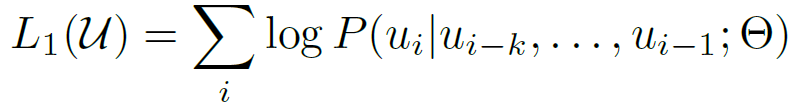
$ u $ : token
$ \Theta $ : parameters
$k$ : window
Unsupervised corpus 를 활용하여 Language Modeling objective 를 통해 pre-training을 진행한다
즉, 앞선 단어들을 통해 다음 단어를 예측하는 language modeling objective 를 사전학습에 활용한다.
위의 수식은, 이를 나타내는데, 앞선 단어들이 주어질 때 다음 단어가 오는 확률을 최대로 하는 parameter를 얻는 목적함수로 이해할 수 있다.

구조로는 Transformer decoder x 12 를 사용한다. 하나의 block은 Masked multi-headed attention, pointwise feed forward layer, layer normalization 으로 이루어진다. 이를 수식으로 나타내면 다음과 같다
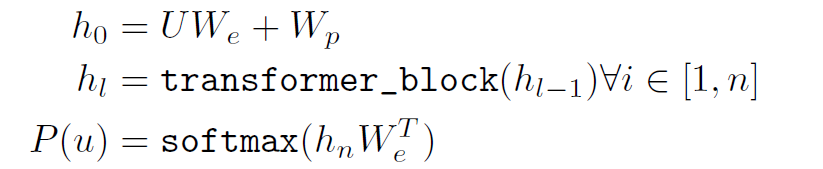
$UW_e$ : embedding vector (Input token vector → embedding layer)
$W_p$ : positional embedding vector
Input token vector가 embedding layer를 통과해서 얻은 embedding vector에, positional embedding vector을 더하여 $h_0$ 을 얻는다.
$h_0$ 을 decoder에 통과시키고,
마지막 layer 에서 나온 output을 전치된 embedding layer의 parameter 와 곱한 후, softmax 에 통과시켜, 가장 확률이 높은 단어를 다음단어로 예측하게 한다.
3.2 Supervised fine-tuning
Labeled Dataset을 통해 target task 를 위한 fine-tuning 을 진행한다.
$x^1, ...,x^m$ 의 input token sequence 가 주어질 때 정답 $y$ 가 나올 probability 를 최대로 하도록 학습한다.
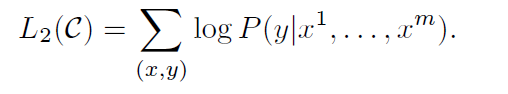
input token sequence을 input으로 넣고, pre-trained 된 모델의 마지막 layer 에서 나온 output 에, softmax 함수를 activation 함수로 갖는 새로운 linear layer 를 통과하게 한다.

최종적인 fine-tuning의 objective 는 해당 목적함수와 사전학습 때의 목적함수를 부가적으로 (auxiliary) 더한 것으로 표현하게 되었다. 이유는, 학습 시 더 나은 task 전반적으로 더 나은 성능을 보여주고 (improvement of generalization) 과 학습 속도를 빠르게 했기 때문이다. (acceleration of convergence) 다만 auxiliary 목적함수에 0.5의 가중치를 둔다.

새로 추가된 parameter 은 embedding layer의 delimeter token 에 해당하는 vector와 마지막 linear layer의 parameters 이다.
3.3 Task-specific input transformations
GPT 의 fine-tuning 시에 각 task 에 맞게 학습방식과 input 을 변행했다.

Textual entailment : premise $p$, hypothesis $h$ 의 token sequence 를 delimeter token 으로 이은 vector 를 input vector 로 사용한다.
Similarity : 두 문장 token sequence 를 delimeter token 으로 이은 쌍을 가능한 sentence ordering 대로 input vector를 모두 생성한다. 이들을 input으로 했을 때 transformer 를 통과한 output 들을 element-wise sum 하고, 마지막 linear layer 을 통과시킨다.
Question Answering Commonsense Reasoning :
document $z$, question $q$, delimeter $, set of possible answers {$a_k$}
하나의 example 에 대해 [$z;q;\$;a_k$] 형식으로, k개의 input vector를 생성한 후, 이들을 각각 transformer 에 통과시킨다. 각 output 들에 softmax 연산을 적용하여 정답여부에 따라 1 또는 0 이 나오게 만든다.
4. Experiments
4.1 Setup
Unsupervised pre-training
- BooksCorpus : 7,000 unique unpublished books (Adventure, Fantasy, and Romance)
- BooksCorpus 활용 이유 : 데이터셋에 긴 문장들이 연속적으로 이어지기에, 긴 길이의 문맥을 학습하기에 적절할 것으로 판단하여 활용했다
- 1B Word Benchmark : ELMo 에서 사용, 문장 레벨로 shuffle 해서 학습했다.
Model specifications
- Decoder x 12 Layer (Block)
- masked self-attention : 768dim, 12 attention heads
- position-wise feed-forward networks : 3072 dim
- Adam (max lr : 2.5e-4)
- LR Schedule : linear warmup (2000 updates) + cosine annealing
- epochs : 100
- batch size : 64 (random sampled)
- 512 tokens
- weight initialization : N(0, 0.02)
- layer normalization 이 다수 수행되므로 단순한 초기화 방법을 사용
- Dropout : residual, embedding, attention (rate = 0.1)
- Gaussian Error Linear Unit (GELU) 사용
- learned positional embedding (not sinusoidal)
- BPE 40,000 vocab
- Book corpus 전처리 : ftfy library
- punctuation, whitespace 제거
- spacy tokenizer
Fine-tuning details
- Dropout rate : 0.1
- learning rate : 6.26e-5
- batch size : 32
- epochs : 3
- LR Schedule : linear learning rate decay with warmup (전체 step의 0.2%)
- $\lambda$ : 0.5 (language model auxiliary objective)
4.1 Supervised fine-tuning
평가에 활용한 Task 별 데이터셋은 다음과 같다

Natural Language Inference
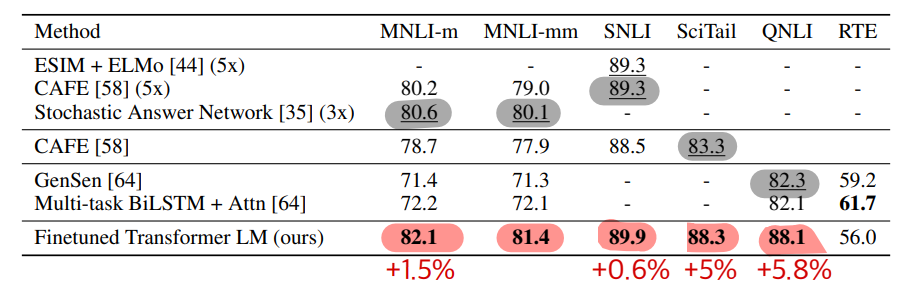
- 문장 관계 분류 (entailment, contradiction or neutral)
- image captions (SNLI), transcribed speech, popular fiction, and government reports (MNLI), Wikipedia articles (QNLI), science exams (SciTail) or news articles (RTE)
- 5개 중 4개에서 (RTE 제외) 유의미한 성능향상이 있었고, 이는 GPT가 여러 문장에 대한 추론 능력과 언어적 모호성 극복 능력이 있음을 보인다
Question answering and commonsense reasoning
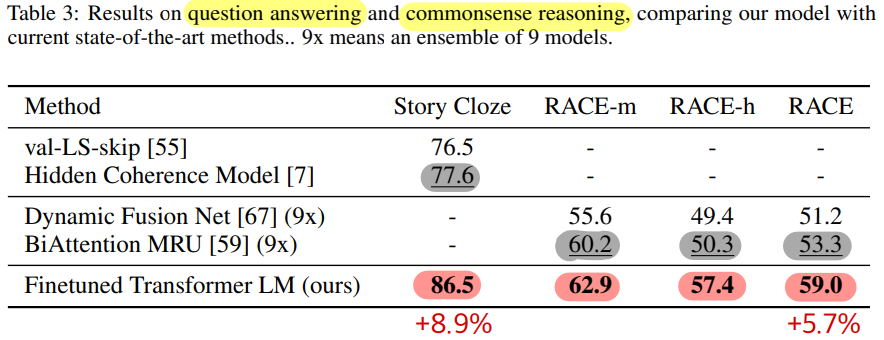
- RACE : 중,고등학교의 영어 단락에 대한 질문이 주어진다. 이는 CNN, SQuaD보다 추론문제가 많다고 알려져있다
- Story Cloze Test : 여러문장 이야기가 주어질 때 두개 선택지 중 결말 예측
- up to 8.9% on Story Cloze, and 5.7% overall on RACE
- GPT가 긴 길이의 문맥을 잘 학습한다
Semantic Similarity and Classification

- Semantic Similarity
- 두 문장에 대해 동일 내용 여부 예측 (paraphrase detection)
- the Microsoft news Paraphrase corpus (MRPC), the Quora Question Pairs (QQP) dataset, the Semantic Textual Similarity benchmark (STS-B)
- 3개 중 2개에서 SOTA 달성 : STS-B (+1.0%), QQP (+4.2%)
- Classification
- CoLA : sentence is grammatical or not ( 모델이 데이터로부터 문법정보(linguistic bias)를 학습했는지 test 하기 위함 )
- Stanford Sentiment Treebank (SST-2) : binary sentiments
- 3개 중 2개에서 SOTA 달성 : STS-B (+1.0%), QQP (+4.2%)
- SST-2 는 SOTA에 조금 덜미치는 성능, CoLA에서는 큰 성능차이(35% → 45.4%), 전반적인 GLUE 에서 유의미한 성능향상 (68.9% → 72.8%)
GPT는 ensemble 모델까지 이기며, 12개 benchmark 데이터 중 9개에서 SOTA를 달성했다. 그리고 성능 우세여부는 데이터셋의 양에 영향을 받지 않았다. (가장 적은 STS-B, 가장 큰 SNLI)
5. Analysis
Impact of number of layers transferred

fine-tuning에 사용한 사전학습 모델의 layer 의 수와 성능 간의 관계를 분석했다.
tranfer learning 에 사용한 사전학습 모델 layer 의 수가 증가할 때, 성능증가가 나타났다. MultiNLI에서는 최대 9% 향상을 보였다.
이는 사전학습의 layer 에서 이미 target task 를 해결하는데 유용한 정보를 가진다는 것을 보여준다.
Zero-shot Behaviors

Transformer 에서의 language model 방식의 pre-training 이 왜 효과적인가를 알아보기 위한 분석이다.
분석의 전제는 Transformer 구조의 모델이 가진 attention 메모리가 LSTM보다 long range 학습에 유리하게 했다는 것과, pre-training 과정에서 해당 모델이 여러 target task 에 도움되는 기능을 학습한다는 것이다.
fine-tuning 없이 target task 성능을 평가하기 위한 실험을 설계하여, task별, 모델 구조별로 pre-training 의 횟수를 변경해가며 결과를 관찰하였다. LSTM 보다 Transformer 에서, pretraining 횟수에 따라 모든 task에서 안정적인 우상향 추세를 보였다.
zero-shot 성능확인을 위한 학습방법은 다음과 같다.
- CoLA (classficiation) : 문장 token 들의 평균 log-probability 를 구한 뒤 threshold 기준으로 class를 예측한다.
- SST-2(classficiation): 각 example 끝에 very 를 붙인 뒤, 다음 token 예측으로 positive, negative 로 제한하여 더 높은 probability 를 가진 class로 예측한다.
- RACE(QA) : document; question 이 주어졌을 때, choice 를 이루는 토큰들 중 가장 높은 평균 log probability 를 가진 answer 로 예측한다.
- DPRD : pronoun 을 가리키는 실제 명사 후보군으로 대체하고, 실제 뒤에 이어지는 token 들의 average log probability 가 높은 경우, 정답으로 간주한다.
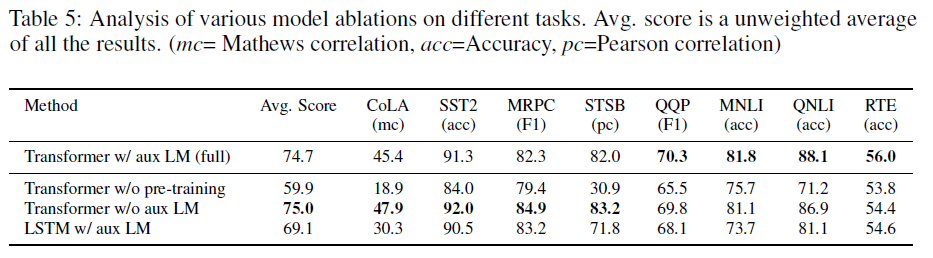
Ablation Studies
- without the auxiliary LM objective during : NLI tasks and QQP 에서 auxiliary 를 추가했을 때 성능이 더 높았다. 큰 데이터셋의 경우 auxiliary 를 추가했을 때 성능이 증가했지만, 비교적 작은 데이터셋은 그렇지 않았다. auxiliary objective 의 영향은 데이터셋 크기에 따라 달라질 수 있음을 시사한다.
- Transformer vs LSTM(single layer, 2048) : LSTM 모델이 MRPC 를 제외하고는 Transformer 보다 낮은 성능을 보이며 평균 5.6% 성능감소를 보였다. 이로써 Transformer 구조를 사용의 효과가 유의미함을 보였다.
- Unpretrained vs Pretrained : 사전학습을 하지 않은 transformer는, 기존 모델보다 평균 점수에서 14.8% 감소를 보이며 task 전반적으로 성능 감소를 보였다. 이로써 사전학습(Pre-train)의 효과가 유의미함을 보였다.
6. Conclusion
- GPT는 NLU 에서 우세한 성능을 보여준, generative pre-training 와 discriminative fine-tuning 을 결합한 단 하나의 task-agnostic model 이라는 것에 의의가 있다.
- GPT는 Transformer 을 사용함으로써 long-range dependency 를 잘 학습한다는 것을 보여준다.
- 4가지 NLP task 에 속한 12 개 중 9개의 데이터셋에서 SOTA를 달성했다.
스터디원들과의 QnA 및 Discussion
(5. Analysis Ablation Study) 구조에 따른 성능 차이를 위한 분석에서, 왜 2048 뉴런의 single layer 의 LSTM 과 Transformer를 비교했을까? LSTM을 깊게 쌓거나 attention 을 추가한 구조와 Transformer 을 비교해서 나온 결론이 더 설득력이 있지 않았을까?
혹시 parameter 수가 비슷해서 비교했을까? 아닌듯하다. 해당구조의 LSTM 파라미터 수는 23,076,864 ( 4*h*(h+dim+1) )로 약 23M 이다. Transformer 의 12 block 의 parameter 는 85M 로 파라미터를 훨씬 많이 가지고 있다. 따라서 파라미터 기준으로 모델을 구성해서 비교한 건 아닌 것으로 보인다.
Naive 한 구조 간의 비교를 하는데 의의를 두고, Single Layer LSTM vs Transformer 를 수행했을 것이다 라는 동료분의 생각에 한표를 던지게 되었다. Reviewer 입장에서도 선행연구들에서 Transformer 의 우세를 알고 있기에, 이러한 simple 한 생각에 기초를 둔 비교 frame 에 크게 이의를 제기하지 않았을 가능성이 크다고 생각되기 때문이다.
(5. Analysis zero-shot behavior) "For RACE (question answering), we pick the answer the generative model assigns the highest average token log-probability when conditioned on the document and question."
'zero-shot 평가에서 document와 query를 input 으로 넣었을 때, target 은 answer 하나인데, the highest token log-probability 가 아닌, the highest average token log-probability 로 적혀있을까? 왜 average 라는 개념이 들어갈까?'
스터디원분이 생각을 develop 해준 덕분에 해당 의문에 대한 유력한 답변을 유추해볼 수 있었다. answer 은 wordpiece의 tokenizer 의 vocab 에 속한 여러 token 으로 이루어졌을 가능성이 크다. (answer이 word-level, phrase-level, sentence 셋 중 어느것이어도 분절될 수 있기 때문이다)
결국 zero shot 예측에서, 각 answer 후보를 구성하는 token 들의 log probability 평균을 비교하여 answer을 선택하는 방식으로 예측을 수행한 것으로 생각된다.
(3.3 Task-specific input transformations 의 Question Answering) figure를 보면 하나의 example 당 choice 개수만큼의 output 이 나오게 된다. 정답의 shape 나 input 의 shape 와 같은 데이터셋의 구성이 정확하게 그려지지 않는다
이해를 위해 하나의 example, label 기준으로 생각해보면 (당연히 batch 단위로 계산되겠지만), choice 별로 각각의 output 을 얻어 concat하면 (1, n_choice) 의 벡터를 얻고, softmax 연산을 통해 해당 벡터를 합이 1인, 확률값들을 가진 벡터로 변환될 수 있다. 원핫인코딩 된 label 을 생각해보면 (1, n_choice)로, concat된 output과 shape 와 일치할 것이고, 결국 하나의 example 에 원핫인코딩된 label 하나가 대응되도록 구성하면 된다는 것을 알 수 있다. 동일하게 학습 때는 generator 에서 batch 개의 input과 ohe_target pair을 뽑을 것이다.
(3.2 Supervised fine-tuning) fine-tuning 에서의 objective 는 auxiliary objective 까지 2개로 이루어졌다. 학습 시에 각 objective 에 해당하는 loss 계산은 동시에 이루어질까?
official code 를 참조했을 때, Fine-tuning 시에 동시에 계산한 2개의 loss 의 합이 최종 loss 로써 parameter update 에 사용되는 것을 알 수 있다 (아래 코드). 특히 language modeling 를 학습할 때는 target 을 제외한 input만 으로 shifted input 을 예측하는 방법으로 구현한 것을 알 수 있다.
# inputs of LM (마지막 token 제외): input[batch, :-1, :]
# targets of LM (첫 token 제외) : input[batch, 1:, :]
with tf.device(assign_to_gpu(i, "/gpu:0")), tf.variable_scope(tf.get_variable_scope(), reuse=do_reuse):
clf_logits, clf_losses, lm_losses = model(*xs, train=True, reuse=do_reuse)
if lm_coef > 0:
train_loss = tf.reduce_mean(clf_losses) + lm_coef*tf.reduce_mean(lm_losses)
else:
train_loss = tf.reduce_mean(clf_losses)
(3.2 Supervised fine-tuning) auxiliary objective 에 0.5를 곱한 이유는 무엇일까?
Fine-tuning 시에 해당 downstream task 에서 주어진 x에 대해 y를 예측하는 log-probability 추가로 하는 objective 가 main objective 가 되어야한다. Auxiliary objective 는 성능향상과 학습에 도움이 되지만, main objective 보다는 낮은 가중치를 가지고 학습에 기여하기를 희망했을 것이고, 가중치 0.5라는 값은 실험적으로 찾아낸 것으로 생각된다.
<Reference>
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.





댓글 영역