고정 헤더 영역
상세 컨텐츠
본문 제목
(BERT) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰 (feat. SQuAD fine-tuning Code)
본문

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰
Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다
Abstract

- Deep bidirectional representation : 모든 layer에서 양쪽 방향의 문맥을 학습하는 모델이다
- 여러 task에서 단 하나의 output layer를 추가하는 방식으로 fine-tuning 을 수행할 수 있다 (GPT의 fine-tuning 이 비교적 복잡했던 task들 또한 해당된다)
- 개선방식은 simple, 성능은 powerful 하다
- GLUE 7.7% 향상
- MNLI acc 4.6% 향상
- SQuAD v1.1, v2.0 각각 F1 1.5%, 5.1% 향상
1. Introduction
BERT 이전까지, GPT를 포함한 Language model 기반의 사전학습 모델이 좋은 성능을 보여주었다.
이러한 사전학습 모델의 representation 을 downstream task 에 사용하는 방식은 선행연구에서의 모델들로 나누자면, 2가지로 나눌 수 있다.
- feature-based approach
- ELMo
- downstream task 에 사용할 task-specific architecture 가 추가로 필요하다
- pre-trained representation 을 embedding vector, 즉 fixed feature로 사용할 뿐이다.
- fine-tuning approach
- GPT
- minimal task-specific parameters (GPT에서는 single linear layer)
- 모든 pre-trained parameter를 업데이트한다
공통점은 두 가지에 해당되는 모델 모두 language modeling 을 objective 로 쓰기에, unidirectional 한 representation 을 학습한다는데 있다. (self-attention 연산 시 previous 토큰들만 사용)
그런데 이것은, QA와 같은 token-level task 의 성능을 크게 저하시킬 수 있다.
BERT는 fine-tuning 기반 모델의 이러한 약점을 보완할 수 있다.
기존의 language model objective를 Cloze task 라고도 불리는 “masked language model” (MLM) 으로 pre-train objective를 수정했다. MLM은 문장의 일부를 랜덤하게 마스킹하고, 마스킹 된 토큰에 위치한 원래 토큰을 예측하는 문제이다. 이를 학습하기 위해, 모델은 기준 토큰의 양쪽 문맥을 모두 학습할 수 있다. 또한 “next sentence prediction” (NSP) 을 MLM과 함께 objective 로 사용하여, text-pair representation 얻을 수 있었다.
논문의 contribution 은 아래와 같다.
- GPT, ELMo 와 달리 BERT는 MLM을 통해 bidirectional pre-training for language representations 을 얻을 수 있으며, 실험을 통해 이의 중요성을 시사한다.
- fine-tuning 시 task-specific한 무거운 architecture를 추가적으로 사용하지 않으나, 많은 sentence-level, token-level task에서 성능은 SOTA를 달성했다. (11 NLP Task)
2. Related Work
2.1 Unsupervised Feature-based Approaches
Pre-training을 통해 좋은 representation 을 얻는 방법에 대한 연구들은 word-level에서 sentence-level 로 이어져왔다. 대표적인 예가 ELMo 인데, Left to Right, Right to Left 방향으로의 contextual feature를 concat 함으로써, 양방향의 sentence-level contextual representation 을 얻을 수 있었다. 이는 task-specific architecture를 가지는 모델에서 feature로 사용되므로 ELMo는 feature based 방법에 속한다.
MLM 또한 선행연구에서 LSTM과 함께 쓰이거나 text generation 에 활용되었으나, deep bidirectional 하지는 않았다. 이는 모든 layer에서 bidirectional 하게 학습하지는 못했다는 것을 의미한다.
2.2 Unsupervised Fine-tuning Approaches
이전에는 Unlabeled 데이터셋에 대한 사전학습을 통해 word-level의 representation 을 얻고, 이를 모델의 embedding vector로 사용하는, 이른바 feature based 방식이 존재했다.
최근에는 GPT와 같이, sentence-level의 contextual representation 을 Unlabeled 데이터셋의 사전학습으로부터 얻고, downstream task 에서 fine-tuning 진행하는 방식을 사용하고 있다. fine-tuning에서는 적은 수의 파라미터만 새로 학습하면 되어 속도가 빠르다는 장점이 있다. (random initialize 후에 학습되는 파라미터가 소수이기 때문이다)
2.3 Transfer Learning from Supervised Data
NLP의 NLI, 기계번역, CV의 Image Classfication 영역의 선행연구들을 통해, 대량의 데이터셋을 사전학습한 모델로 downstream task에 transfer learning 을 수행했을 때, 더 나은 성능을 보이는 것을 알 수 있다.
3. BERT
pre-training + fine-tuning : BERT는 unlabeled 데이터를 pre-train한 모델을 각각의 downstream task에 맞게 fine-tuning 시키는 과정을 가진다.
특히 BERT는 모든 task의 fine-tuning에 동일구조를 사용하는 장점이 있다. 각각의 task에서 Classification layer 만을 추가로 더하면 되기 때문에 minimal 한 수정이 요구된다고도 할 수 있다.
Model Architecture
BERT는 Transformer encoder 기반의 구조를 가진다. L은 layer의 수, H는 hidden size, A는 attention head의 수를 나타내며, 논문에서는 모델의 크기가 다른 두가지의 BERT를 제시한다.
- BERT-BASE (L=12, H=768, A=12, Total Parameters=110M) : OPENAI GPT 와 비교목적으로 동일한 크기로 훈련했다. self-attention 에서 GPT는 unidirectional 하고 BERT는 bidirectional 하다는 차이점이 존재한다.
- BERT-LARGE (L=24, H=1024, A=16, Total Parameters=340M)
Input/Output Representations
downstream task 에 적용할 때, a single sentence 나 a pair of sentences 의 입력이 필요한데, BERT에서는 이를 일관되게 하나의 token sequence로 사용한다는 특징이 있다.
Wordpiece를 통해 30,000 token 의 vocab을 학습했다.
입력을 구성할 때는 항상 special classification token ([CLS])이 첫번째가 되며, Classfication 에서는 [CLS] 위치의 값을 예측에 사용한다. 여러 문장을 넣을 경우, 문장 간에 [SEP] 토큰을 넣어 문장을 구분해준다.
input sequence에 대한 최종적인 embedding vector는 아래 3개의 vector을 summation 하여 생성된다.
- token embedding vector : input sequence 에 대한 representation을 embedding layer에서 학습- 한다.
- segment embedding vector : 문장을 구분해주는 embedding vector로 Ti(i번째 token)가 문장 A에 속하면 0, 문장 B에 속하면 1의 값을 가진다.
- positional embedding vector : 토큰 간 상대적인 위치를 더 잘 학습하도록 한다.
3.1 Pre-training BERT
Task #1: Masked LM (MLM, Cloze task)
Input sequence 의 일부를 random하게 masking하고, masking 된 원래의 token 을 예측하는 문제를 사전학습의 objective로 설정하였다. 실험을 통해 sequence 당 masking 비율은 15% 를 사용하였다.
그러나, 15%을 모두 [mask] 로 대체하는 것은 아니다. 그 이유는, fine-tuning 에서는 [mask] 토큰이 사용되지 않으므로 mismatch 에 의해 성능저하 가능성이 존재하기 때문이다. 따라서, 이를 완화하기 위해 input sequence token 들의 15% 에 대해 8:1:1의 비율로 “[mask]” 토큰으로 대체 (MASK), random token으로 대체 (RND), 원래 token을 유지 (SAME) 하는 방법을 적용했다.
- 80% of random 15% : [mask]
- my dog is hairy → my dog is [MASK]
- 10% of random 15% : random token
- my dog is hairy → my dog is apple
- 10% of random 15% : unchanged
- my dog is hairy → my dog is hairy
하나의 pair 당 15%만을 예측에 사용하므로, Left to Right (LTR) 모델보다 학습 속도가 느렸으나(converge marginally slower), 이를 감수할만큼 효과는 유의미하였다.
Task #2: Next Sentence Prediction (NSP)
여러 문장을 다루는 sentence-level 의 task에서 language modeling objective는 문장 간 관계에 대한 맥락을 직접 학습하지 못한다. 이를 보완하기 위해 NSP objective 가 추가되었다.
50% 는 이어지는 두 개의 문장으로 sequence를 구성하여 “IsNext” 라는 Label 을 갖게하고, 50% 는 두개의 문장을 random하게 구성하여 “NotNext” 라는 Label을 가지게 함으로써 문장의 연속성을 학습하고 예측하도록 했다. 의도대로 Question Answering (QA), Natural Language Inference(NLI) 에서 NSP가 성능향상을 견인했다는 것을 보여준다. (section 5.1)
# NSP 학습 pair 예시
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext선행연구에서 NSP 를 사전학습의 objective로 활용했으나, sentence embedding만을 downstream task 에서 사용했다. BERT의 경우 사전학습 모델의 모든 파라미터를 활용한다.
Pre-training data
- BooksCorpus (800M words) + English Wikipedia (2,500M words) 에서 text passage만을 사용했다.
- 길고 연속적인 text sequence를 학습하기 위해 document-level 의 corpus만을 사용했고, 그 결과 Word Benchmark 데이터는 제외되었다.
3.2 Fine-tuning BERT

- 이전에는 text pair 에 대해 각각의 문장을 따로 encode해야 했었다
- 그러나 BERT 는 concat 된 text pair 을 concat 후 한번에 encoding 하여 single sequence를 형성하며 두 문장이 함께 bidirectional cross attention 연산을 수행할 수 있도록 한다.
- 모든 task 에 대해 end-to-end 로 fine-tuning을 진행할 수 있도록 input-output 구성이 가능하다
- Fine-tuning의 연산 또한 빠른편이다. 동일한 사전학습 모델로 진행했을 때, TPU는 한시간, GPU는 수 시간만에 학습이 완료된다.
4. Experiments
BERT-BASE, BERT-LARGE의 11개 NLP Task 에 대한 결과를 공유한다.
4.1 GLUE
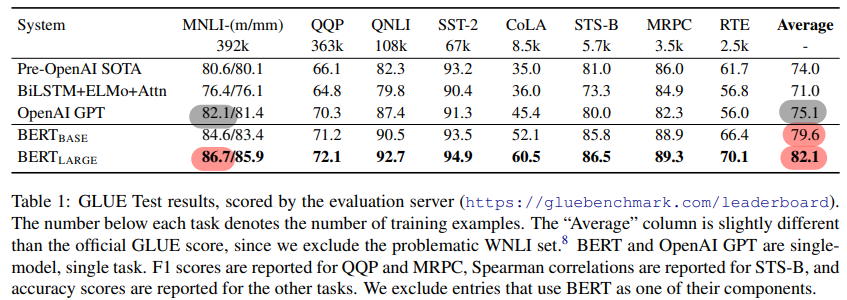
NLU 성능을 평가하는 데이터셋이며, 학습 진행 detail은 다음과 같다
- batch size of 32, 3 epochs for all
- LR selecition on dev-set : 5e-5, 4e-5, 3e-5, 2e-5
- best random start on dev-set : GLUE data shuffling, classifier layer initialization
GLUE 평가결과
- BERT-BASE and BERT-LARGE 는 Average Accuracy 기준으로 각각 4.5% and 7.0% 의 향상을 이루었다
- BERT-LARGE 기준으로 MNLI 에서는 4.6% 향상이 있었다
- 적은 데이터셋에서도 BERT-LARGE 는 BERT-BASE 를 outperform 했다 (일반적으로, 데이터셋이 적으면 무조건 큰 모델이 더 나은 성능을 보여주지는 않는다)
4.2 SQuAD v1.1
- 100k crowdsourced question/answer pairs (Question Answering)
- Wikipedia question and a passage 가 주어질 때, answer span (start, end poistion)을 예측하는 문제
- 3 epochs, LR 5e-5, 32 batch size
- start, end token 을 따로 예측하는 방식으로 구현된다
- 일반적인 single linear layer 추가하는 방식과 다르다
- parameter vector (2, h) 를 생성 (각각 start, end token 예측용)
- BERT outpooled vector (batch, num_vocab, h)에 각 vector (2, h) 와 dot product 수행 → (batch, num_vocab, 2) → softmax (Pi)→ argmax
- Ti의 Start token 확률 : Pi=eS⋅TiΣjeS⋅Ti
- Final span : Maximize S⋅Ti+E⋅Tj (j≥i)
- 아래는 answer를 예측하는 과정의 코드이다. (Input, Label 전처리 코드는 아래에 "스터디원들과의 QnA 및 Discussions" 참조)
# QA 후처리 구현 code
output = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([segment_ids]))
#reconstructing the answer
answer_start = torch.argmax(output.start_logits)
answer_end = torch.argmax(output.end_logits)
if answer_end >= answer_start:
answer = tokens[answer_start]
for i in range(answer_start+1, answer_end+1):
if tokens[i][0:2] == "##":
answer += tokens[i][2:]
else:
answer += " " + tokens[i]
if answer.startswith("[CLS]"):
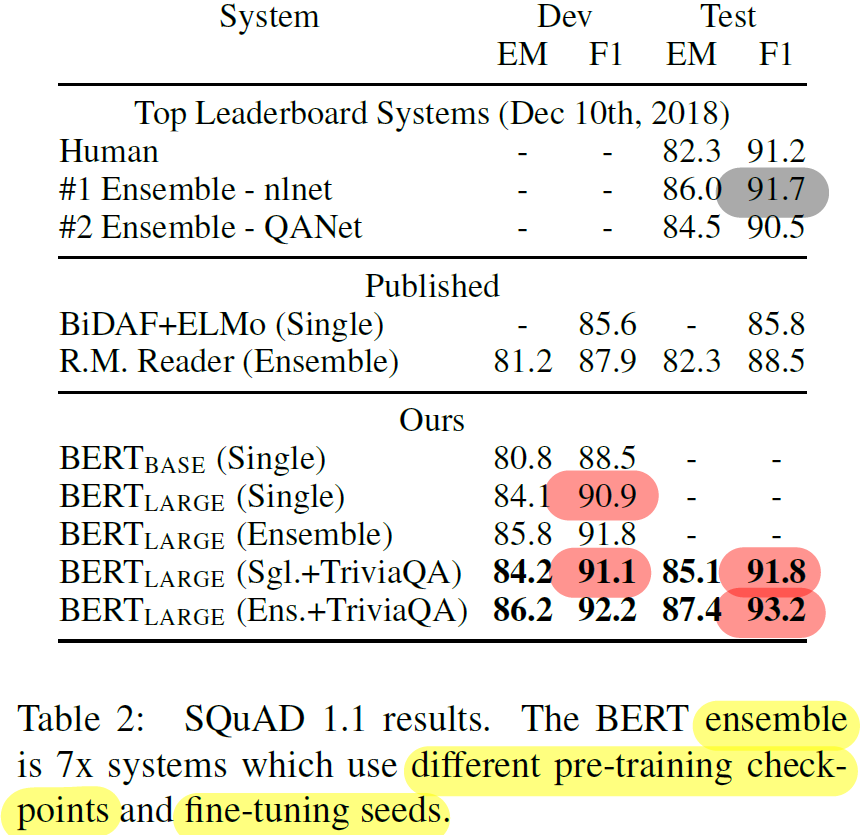
answer = "Unable to find the answer to your question."SQuAD v1.1 결과
- +TriviaQA single / ensemble : F1 1.3 / 1.5 향상
- TriviaQA augmentation 없어도 F1 0.1에서 0.4 정도의 미미한 차이이고, 여전히 타 모델에 비해 우세
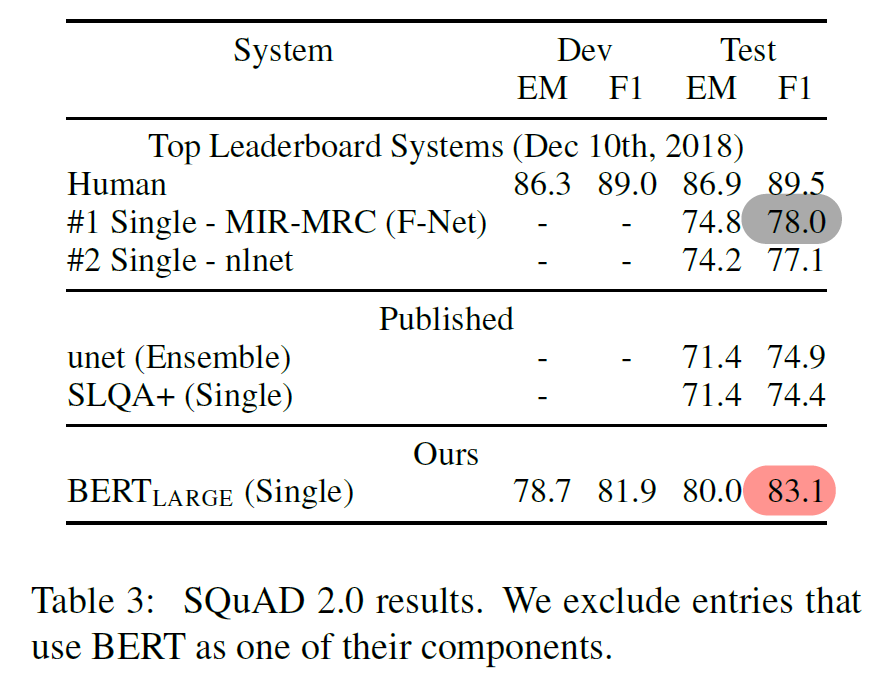
4.3 SQuAD v2.0
SQuAD 1.0 에 비해 짧은 answer 이 없고 “답이 없음” 또한 answer 로 포함한다. 이를 구현하기 위해 answer span 에 [CLS] 를 포함하며,
- null span score 계산 : snull=S⋅C+E⋅C
- not null span score 계산 : ^si,j=maxj≥iS⋅Ti+E⋅Tj
- ^si,j>Snull+τ 을 만족할 때만 non-null answer로 예측한다. 즉, non-null answer로 예측하기 위한 threshold 를 증가시켰다고 볼 수 있다. τ는 dev set에서 F1을 최대로 하는 값을 탐색했다.
- 2 epochs, LR 5e-5, 48 batch
- 결과 : BERT-LARGE 기준 5.1 F1 향상
4.4 SWAG
- 113k sentence-pair grounded commonsense inference
- 4개 선택지 중 가장 이어질만한 문장을 찾는 문제
- input : 두 문장을 concat
- output : [CLS] token 값의 prediction + linear layer + softmax
- 3 epochs, LR 2e-5 and 16 batch size
- 결과 : BERT-LARGE 기준, ESIM+ELMo 대비 27.1% , OpenAI GPT 대비 8.3% 향상

5. Ablation Studies
5.1 Effect of Pre-training Tasks
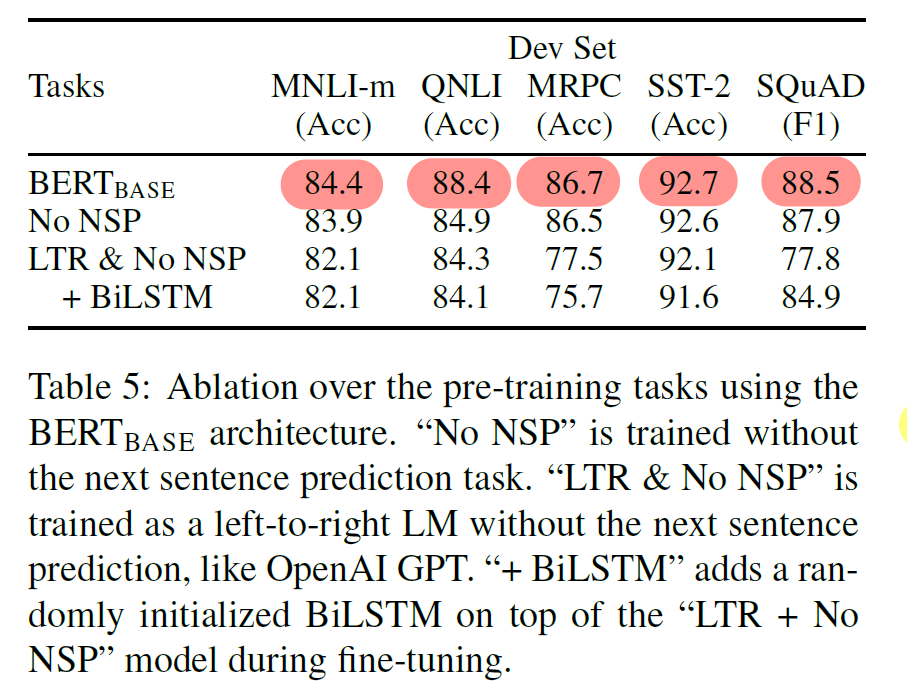
- deep bidirectionality of BERT (MLM, NSP) 의 영향을 분석했다. objective 만 상이하고, 데이터, fine-tuning 방식, 하이퍼파라미터를 동일하게 사용했다.
- BERT vs MLM + No NSP : BERT 대비 QNLI, MNLI, SQuAD v1.1 에서 성능이 하락했다. 이를 통해 NSP 의 성능증가 영향을 확인했다.
- BERT vs LTR + No NSP : BERT 대비 모든 task에서 성능이 하락했다. (MRPC and SQuAD에서 큰 하락) 이를 통해 MLM 의 성능증가 영향을 확인했다.
- BERT vs LTR + BiLSTM (SQuAD) : token-level task 에서의 단순한 LTR 사용은 성능하락이 예상되어, BiLSTM을 top에 더하여 비교를 수행했다. 단순한 LTR 보다 향상되었으나 여전히 BERT 보다 성능이 낮음을 확인했다.
- ELMo 와 같이 LTR 과 RTL 모델을 concat 하는 방법도 있을 것이나 단일 모델 대비 연산이 두배로 증가(LTR, RTL 모델)한다. 뿐만 아니라 QA에서의 RTL 모델은 question을 전제로 answer 를 예측하도록 학습되기에 정확한 학습방향이라 보기 어렵다.
- Deep bidirectional model 은 ELMo 와 달리 모든 layer에서 양방향 context 학습이 가능하다.
5.2 Effect of Model Size
- number of layers (L), hidden units (H), and attention heads (A) 를 달리하며 모델 size 와 fine-tuning 성능 간 관계를 분석했다.
- 객관성을 위해 5 random restart 를 통한 dev-accuracy 평균을 기록했다.
- 데이터가 적고, pre-train과 성격이 다른 task 에서도 larger model 의 성능이 증가한다는 것을 보여주는 첫번째 연구이다. 이는, 사전학습으로 얻은 대량의 parameter를 사용하고, 새로 랜덤하게 초기화한 소수의 파라미터만 추가하기에 이루어진 것으로 볼 수 있다.
- 선행연구들의 model 또한 크지만, BERT-LARGE (340M) 를 통해, size를 더 증가시키면 여전히 성능이 더 증가하는 것을 확인했다 (cf. 235M Transformer in previous study)
5.3 Feature-based Approach with BERT
- 사전학습 BERT를 Feature-based 방식으로 활용할 때의 성능을 도출하였다.
- Feature-based 방식을 사용할 경우, task-specific model 을 사용할 수 있고, 사전학습의 feature만 가져와서 더 작은 모델을 사용할 수 있다는 장점이 있다.
- concate outputs of 4 layers + BiLSTM(768) + classification layer
- Fine-tuning 방식과 0.3 F1 차이 (96.1 vs 96.4) 로, BERT는 Feature-based 방식에도 높은 성능을 보인다

Appendix C.1 Effect of Number of Training Steps
Pre-train k step 에 따른 MNLI Dev accuracy 변화를 통해 사전학습모델의 훈련 step 수의 영향을 분석했다

- 1M vs 500k steps: BERT-BASE 기준 1.0% 의 유의미한 차이가 존재했다. (1M > 500k) 즉, 더 많은 step 의 사전학습을 진행할수록 fine-tuning 모델의 성능 또한 높았다.
- MLM vs LTR Train Cost : MLM 학습이 더 많은 train step 이 요구되어 오래 걸린다. 그러나 학습초반부터 더 높은 성능을 보인다
Appendix C.2 Ablation for Different Masking Procedures
MLM에서의 masking 기법 변화에 따른 성능 변화를 관찰했다
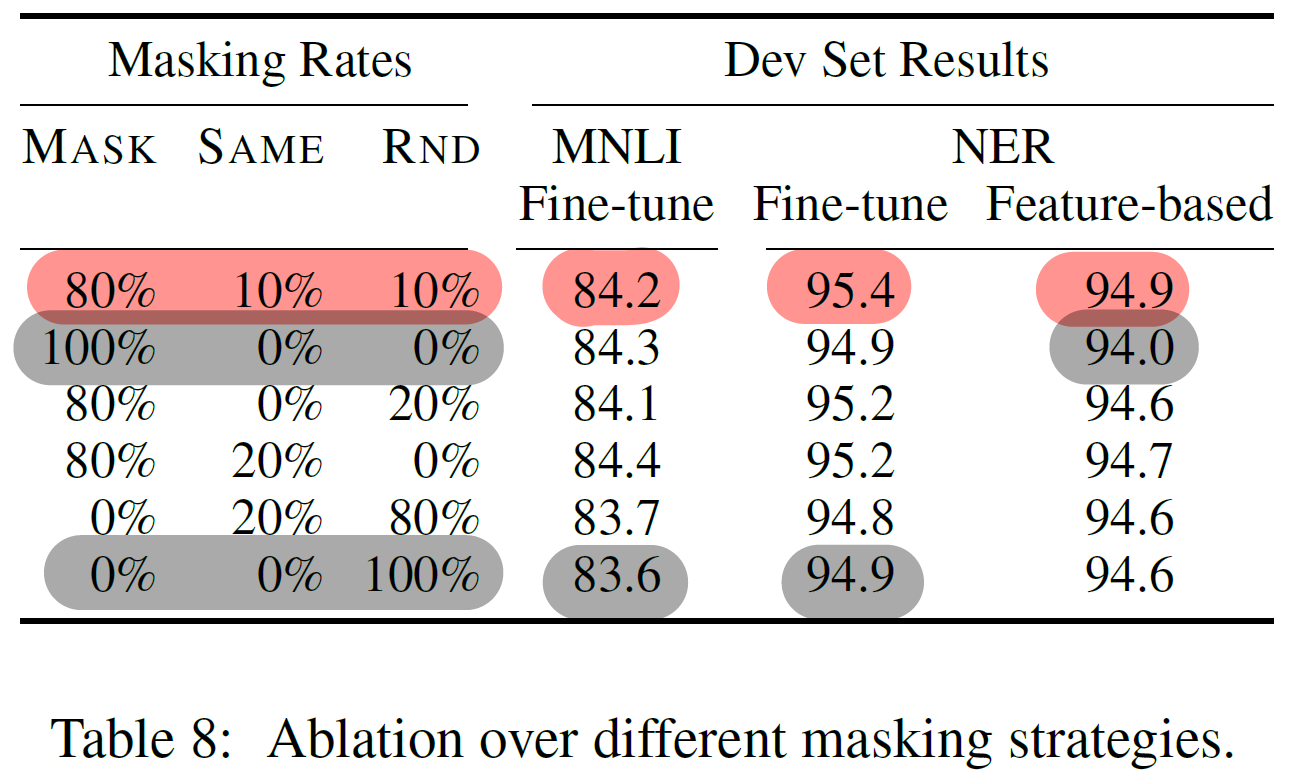
- pre-train 과 fine-tune 간에 불일치를 줄이고 성능을 극대화하기 위한 노력으로 최적의 masking 기법 (8:1:1) 을 탐색했다.
- Fine-tuning 에서 masking 기법 변화에 따른 성능변화가 비교적 robust 했다.
- 100% Masking 기법은 Feature-based에서, 100% Random 기법은 fine-tuning 에서 큰 성능 하락을 보였다.
6. Conclusion
BERT는 Deep bidirectional architectures 가진 unsupervised pre-training 모델로, 데이터가 적은 task를 포함한 여러 NLP task 에서 SOTA를 달성했다.
Appendix. GPT vs BERT 비교
| BERT | GPT | |
| Pre-train Data | BooksCorpus (800M words) + Wikipedia (2,500M words) |
BooksCorpus (800M words) |
| Usage of [SEP], [CLS] | pre-train + fine-tuning | fine-tuning |
| Train size | 128,000 words | 32,000 words |
| Learning Rate | task-specific fine-tuning learning rate | 5e-5 |
Appendix. Experiment Procedure
- Pre-training Procedure
- length : 512 tokens
- 256 Batch size, 4 epochs, 3.3 billion word corpus
- Adam(1e-4, β1 = 0.9, β2 = 0.999), L2 weight decay of 0.01
- LR schedule : linear warmup with 10,000 steps + linear decay
- Dropout rate : 0.1
- GeLU (=OPENAI GPT)
- Loss = mean MLM Likelihood + mean NSP Likelihood
- BERT-BASE, BERT-LARGE : 4 Cloud TPUs (16 TPU), 16 Cloud TPUs (64 TPU)
- 학습 가속 : 90% step 동안 128 token 길이로 학습, 후반 10%는 512 token 길이로 학습
- Fine-tuning Procedure
- 거의 Pre-train 과 동일 : batch size, learning rate, training epoch 제외
- 아래의 범위에서 dev-set 기준으로 최적값 탐색 (fine-tuning 연산이 비교적 light 하므로)
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 2, 3, 4
- Large Dataset 에서는 hyperparameter 값에 따른 성능변화가 크지 않았다.
Appendix. Dataset 설명
| Description | Task | Label | |
| MNLI | Multi-Genre Natural Language Inference; large-scale if second sentence is entailment, contradiction, or neutral |
Classification | Multi |
| QQP | Quora Question Pairs; if two are semantically equivalent | Classification | binary |
| QNLI | Question Natural Language Inference; if (question,sentence) pairs contain the correct answer or not |
Classification | binary |
| SST-2 | The Stanford Sentiment Treebank; sentiment of movie reviews (single-sentence) |
Classification | binary |
| CoLA | The Corpus of Linguistic Acceptability; if linguistically “acceptable” or not |
Classification | binary |
| STS-B | Semantic Textual Similarity Benchmark; news headlines and other sources |
Regression | 1 to 5 |
| MRPC | Microsoft Research Paraphrase Corpus; online news sources; if two are semantically equivalent |
Classification | binary |
| RTE | Recognizing Textual Entailment, small | Classification | binary |
| WNLI | Winograd NLI, small (BERT는 평가에서 제외) |
스터디원들과의 QnA 및 Discussions
Q. SQuAD fine-tuning 에서의 정확한 input / output 구성은 어떻게 될까?
A : input sequence 는 {context; question} 이고, label 은 start token의 위치와 end token의 위치로, 두개가 된다. 코드를 통해 살펴보자.
Input 을 먼저 살펴보자. Input 은 지문과 질문을 concat한 sequence 가 된다. 이를 tokenizing 후 max_len 길이까지 padding 을 하면 된다. segment_embedding_vector는 지문과 질문을 구분할 수 있도록 생성한다. attention_mask 는 패딩을 제외한, 지문과 질문까지만 1의 값을 갖도록 한다. (나머지는 0)
def preprocess(self):
tokenized_context = tokenizer(context, return_offsets_mapping=True)
tokenized_question = tokenizer(question)
...
# Input sequence : context(지문)와 question(질문)의 concat
input_ids = tokenized_context.ids + tokenized_question.ids[1:]
token_type_ids = [0] * len(tokenized_context.ids) + [1] * len(tokenized_question.ids[1:])
attention_mask = [1] * len(input_ids)
padding_length = max_seq_length - len(input_ids)
# max_len까지 padding 수행
if padding_length > 0:
input_ids = input_ids + ([0] * padding_length)
attention_mask = attention_mask + ([0] * padding_length)
token_type_ids = token_type_ids + ([0] * padding_length)
elif padding_length < 0:
self.skip = True
return
다음은 Label 이다. 데이터셋에서는 answer 로 주어지는 것이 지문 내에 존재하는 단순 텍스트이기 때문에, 해당 answer 의 지문 내 start token 위치와 end token 위치를 찾아서 Label로 사용해야한다. Huggingface 의 transformers 에서 return_offsets_mapping 인자를 사용하면, 분절된 토큰 각각에 대해 지문에서의 character idx 범위를 반환하기 때문에 작업이 편리해진다.
train_text = "I love machine learnining, specifically NLP:)"
tokenized = tokenizer(train_text,
return_offsets_mapping=True) # 각 token의 char_idx 범위 반환
print(tokenized)
print(tokenizer.convert_ids_to_tokens([101, 102])) # [CLS], [SEP]
print(tokenizer.tokenize(train_text))
print(tokenized.offset_mapping) # (start_charidx, end_char_idx) of token
"""
{'input_ids': [101, 146, 1567, 3395, 3858, 16534, 117, 4418, 21239, 2101, 131, 114, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 1), (2, 6), (7, 14), (15, 20), (20, 25), (25, 26), (27, 39), (40, 42), (42, 43), (43, 44), (44, 45), (0, 0)]}
['[CLS]', '[SEP]']
['I', 'love', 'machine', 'learn', '##ining', ',', 'specifically', 'NL', '##P', ':', ')']
[(0, 0), (0, 1), (2, 6), (7, 14), (15, 20), (20, 25), (25, 26), (27, 39), (40, 42), (42, 43), (43, 44), (44, 45), (0, 0)]
"""
offset_mapping을 활용하면, 아래의 전처리 코드를 통해 지문 내 answer 의 start token 위치와 end token 위치로 이루어진 Label 을 준비할 수 있다.
def preprocess():
tokenized_context = tokenizer(context, return_offsets_mapping=True)
tokenized_question = tokenizer(question)
...
# context(지문)에 대해 char 단위의 배열을 생성하여, 정답인 부분만 1로 표시 (나머지는 0)
is_char_in_ans = [0] * len(context)
for idx in range(self.start_char_idx, end_char_idx):
is_char_in_ans[idx] = 1
ans_token_idx = []
# token의 char 범위 순회하며 정답에 속하면, 지문 내 해당 token의 순서를 저장
for idx, (start, end) in enumerate(tokenized_context.offset_mapping):
if sum(is_char_in_ans[start:end]) > 0:
ans_token_idx.append(idx)
if len(ans_token_idx) == 0:
self.skip = True
return
# start_token_idx : answer 첫번째 token의, 지문 내 token 순서
# end_token_idx : answer 마지막 token의, 지문 내 token 순서
self.start_token_idx = ans_token_idx[0]
self.end_token_idx = ans_token_idx[-1]
Q. (Introduction) 왜 bidirectional representation 의 한계가 sentence-level task와 달리 token-level task 에 악영향을 줄까?
A : 앞에 참조할 수 있는 단어의 개수가 적고/많음의 차이가 있기 때문이다.
unidirictional 하게 학습할 경우 특정 token 의 이전 token 들만 참조하게 되는데, sentence-level task에서 token-level task 보다 input sequence 길이와 정보를 많이 가질 가능성이 크므로, 앞쪽에서 참조할 정보가 더 많을 가능성이 크다.
그러므로 token-level task에서 unidirectional 할 때의 성능 차이가 더 크다고 볼 수 있다.
Q. (5.3 Ablation Study - Feature-based) 에서 We use the representation of the first sub-token as the input to the token-level classifier over the NER label set. 의 의미는?
A : NER에서는 하나의 word 당 하나의 tag 를 예측하는 many-to-many task 인데, tag 에 속한 한 단어가 여러 token으로 이루어지기에 이를 sub-token 으로 표현하였다. 그래서 해당문장이 의미하는 바는, '문장에 속한 여러 단어의 tag들을 예측하기 위해서, 각 word를 이루는 첫번째 token 에 대한 representation 들만을 classifier 에 input 으로 사용한다' 라고 이해할 수 있다.
input : ['BE', '##RT', 'is', 'bid', '##irect', '##ional', 'language', 'model']
label : ["noun", "X", "verb", "ad", "X", "X", "noun", "noun"]<Reference>
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
(StackExchange) "What should be the labels for subword tokens in BERT for NER task?" :
What should be the labels for subword tokens in BERT for NER task?
For any NER task, we need a sequence of words and their corresponding labels. To extract features for these words from BERT, they need to be tokenized into subwords. For example, the word 'infrequ...
datascience.stackexchange.com
(Medium) QA fine-tuning with BERT :
Fine Tuning BERT for Text Classification and Question Answering Using TensorFlow Framework
A Comprehensive Guide To Fine-Tuning BERT For Text Classification And SQuAD Tasks
medium.com





댓글 영역