고정 헤더 영역
상세 컨텐츠
본문 제목
XLNet: Generalized Autoregressive Pretraining for Language Understanding 논문 리뷰
본문

XLNet: Generalized Autoregressive Pretraining for Language Understanding 논문 리뷰
Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다
<XLNet 한줄요약>
XLNet 은 긴 길이의 문맥 학습을 효과적으로 할 수 있는 Transformer-XL 구조를 사용했으며, permutation language modeling 을 사전학습의 objective로 사용함으로써, AR 및 AE 의 장점을 모두 갖춘 모델이다.
Abstract

- 기존 SOTA 모델인 BERT 한계점
- Pre-training 에서 사용하는 masking 기법은 fine-tuning과의 차이를 발생시키는 한계를 지닌다
- Masking 된 token 간 문맥에서의 의존성을 학습하지 못한다
- XLNet
- token 순서 구성에 대해 permutation을 이용하여, 양방향 문맥을 학습할 수 있게 된다
- 전통적인 AutoRegressive 방식의 한계와 BERT의 한계를 극복한다
- Transformer-XL을 backbone으로 사용했으며, 20개의 Task에서 SOTA를 달성한 Autoregressive model
1. Introduction
Unsupervised representation learning 연구 흐름 지속
- large-scale unlabeled text → pre-training
- Autoregressive (AR) language modeling
- Autoencoding (AE)
- fine-tuning
AutoRegressive (AR) vs AutoEncoding (AE)
- AutoRegressive (AR) language modeling
- p(x)=ΠTt=1p(xt|x<t) : forward product
- p(x)=Π1t=Tp(xt|x>t) : backward product
- uni-directional context
- AutoEncoding (AE)
- masking 된 input sequence를 복원 : mask 토큰의 원래 토큰을 예측
- 위의 objective 를 통한 학습과정에서 bidirectional context 를 학습하게 된다
- 한계점
- fine-tuning 과의 discrepancy 존재: [MASK] 토큰이 fine-tuning 과정에서 존재하지 않는다
- masking 된 토큰 간의 연관성 또는 의존성을 학습할 수 없다 (BERT의 이러한 특성은 특히, 길이가 긴 단위가 주인 task에만 지나치게 초점이 맞추어져있다고 볼 수 있다, 반대로 말하면 작은 단위 중심의 task 에서 이러한 특성은 큰 한계가 될 수 있다.)
XLNet
- sequence 내 token 순서 구성에 대해 모든 가능한 경우의 수를 학습한다
- permutation of factorization of order
- 이를 통해, 각 위치의 토큰은 모든 위치의 문맥 정보를 사용할 수 있어, 양방향 문맥을 학습
- AR Model 이기에, Data Corruption 을 사용하지 않는다.
- BERT 한계점 개선
- pretrain-finetune 간에 discrepancy를 해소한다
- 예측된 token을 다시 joint-probability 계산에 활용할 수 있게 되면서 (AutoRegressive) 예측된 token 간에 dependency를 학습할 수 있다
- BERT 한계점 개선
- Transformer-XL 기반의 구조 활용
- Segment Recurrence mechanism + Relative Encoding scheme
- long text sequence 을 활용하는 능력이 향상되었다
- Two stream attention 활용
- permutation of factorization order 사용 과정에서 생긴 target 예측 모호성 발생
- Transformer-XL 구조 변형을 통해 해결 (two-stream attention: query stream; content stream)
- Segment Recurrence mechanism + Relative Encoding scheme
- SOTA
- Language Understanding (GLUE)
- Reading Comprehension (SQuAD, RACE)
- Text Classification (Yelp, IMDB)
- Document ranking (ClueWeb09-B)
Related Work
선행연구에서 permutation-based AR modeling 기법을 사용한 연구에서는 permutation 의 직관적인 활용 효과에 따라 순서 개념이 없는 bias를 모델에 활용하는 것을 볼 수 있었다.
그러나 XLnet에서는 permutation 에 따라 target이 모호할 수 있는 부분을 명확하게 하고, two-stream attention 사용을 통해 방향성의 개념을 유지하며 문맥을 학습한다는 차이점이 존재한다. (target token 기준으로 양방향 문맥 학습)
즉, 단순히 문장 구성 순서를 섞어 순서개념을 없앤 것이 아니라, 여러 순서에 대한 정보가 의미있게 학습되도록 한 것이다.
2. Proposed Method
2.1 Background
(AR vs AE) Objective
AR Objective : x 토큰 이전 맥락이 주어질 때 x 토큰을 예측
AE Objective : masking 된 token ˆx 에 대해 원래 token x 를 예측
* masking 된 token일 때는, mt 값은 1, 그렇지 않으면 0
(AR vs AE) Pros and Cons
- Independence Assumption : AR > AE
- AR : 모든 token 이 product rule로 계산되어 pθ(x) 계산
- AE : masking 된 token 간에는 factorization 시 서로를 제외 (masking 된 token 간 독립 가정)
- Input noise : AR > AE
- AR : pre-train, fine-tune 간 sequence 구성 일치 ([MASK] 사용X)
- AE : [MASK] token 에 의한 pre-train - fine-tune 간 discrepancy 발생
- Context dependency : AR < AE
- AR : hθ(x1:t−1) 은 학습과정에서 t 위치 이전의 문맥만 사용하도록 학습
- AE : Hθ(x)t는 양방향 문맥을 모두 학습
2.2 Objective : Permutation Language Modeling
- 양쪽 모든 위치에서의 문맥 정보를 활용 : 양방향 문맥 활용
- token xzt 기준으로 모든 순열 case (z) 에서 자신 이전의 토큰 정보를 학습함으로써 자신을 제외한 모든 위치의 문맥 정보를 학습에 사용하게 된다.
- 단, 원래 sequence 내 순서 정보를 유지하기 위해 positional encoding 을 사용한다
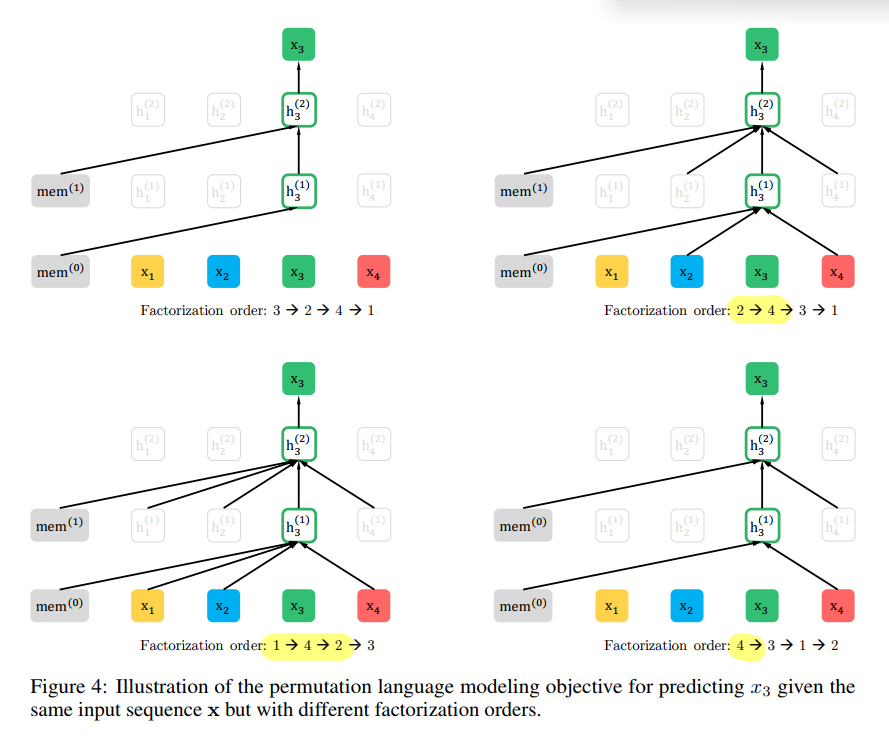
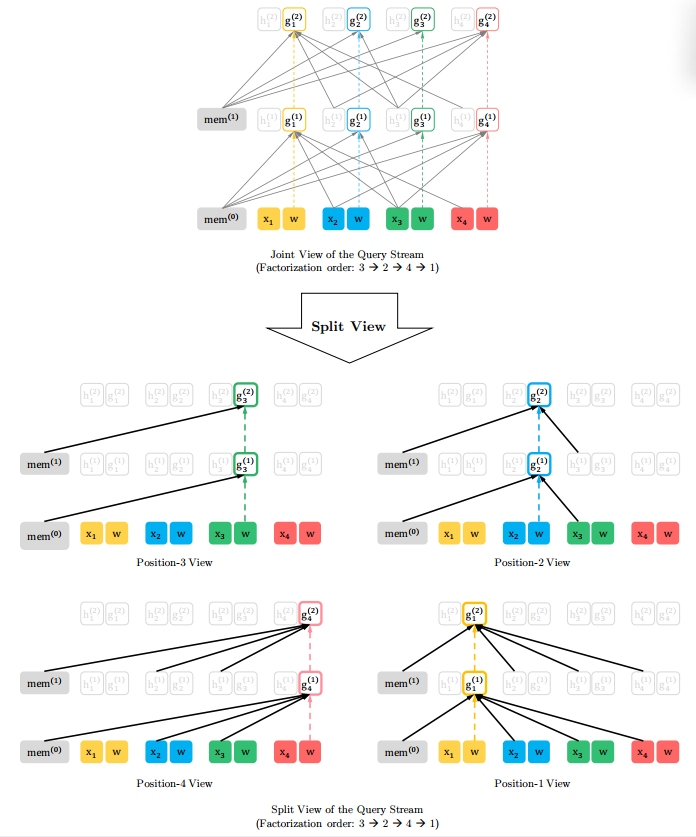
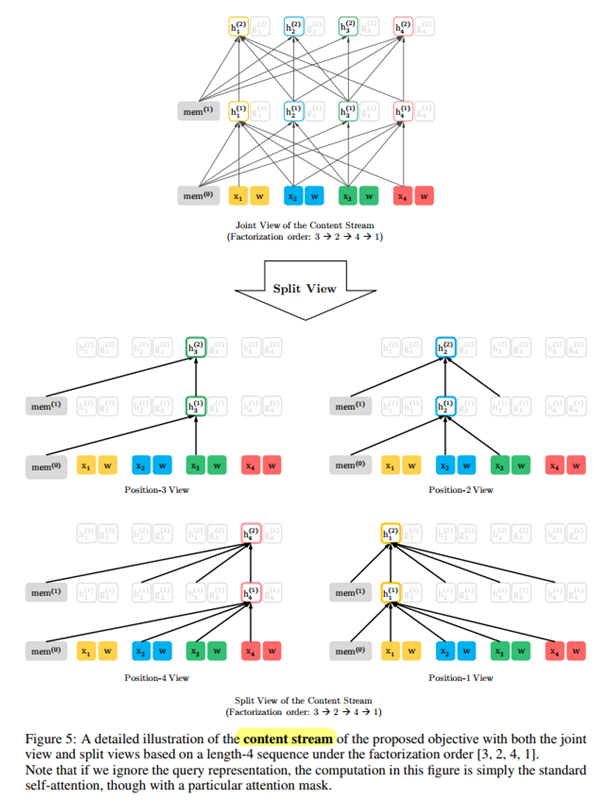
2.3 Architecture : Two-Stream Self-Attention for Target-Aware Representation
Standard Attention 을 그대로 사용할 때의 문제 : Target 에 대한 Ambiguity
- Standard Transformer Attention 사용 시,
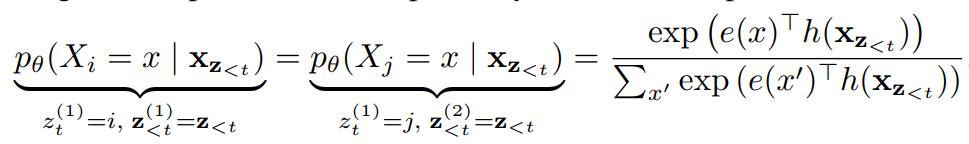
2) 수정된 Attention 연산
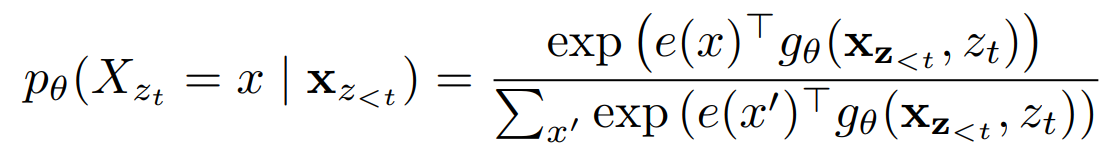
1)을 2)로 수정해야한다. 왜그럴까?
permutation z 에서 t 위치 이전의 문맥을 사용해서 target을 예측할 때, 동일 문맥을 사용하여 서로 다른 target을 예측해야하는 경우가 생긴다. 이를 target 에 대한 ambiguity 라고 한다.
아래 case를 통해 이해해보자.
(동일한 문맥 [2, 3]을 가지고 1과 4를 각각 올바르게 예측해야 한다?? → target 예측의 모호성)

문제해결 : Two-Stream Self-Attention
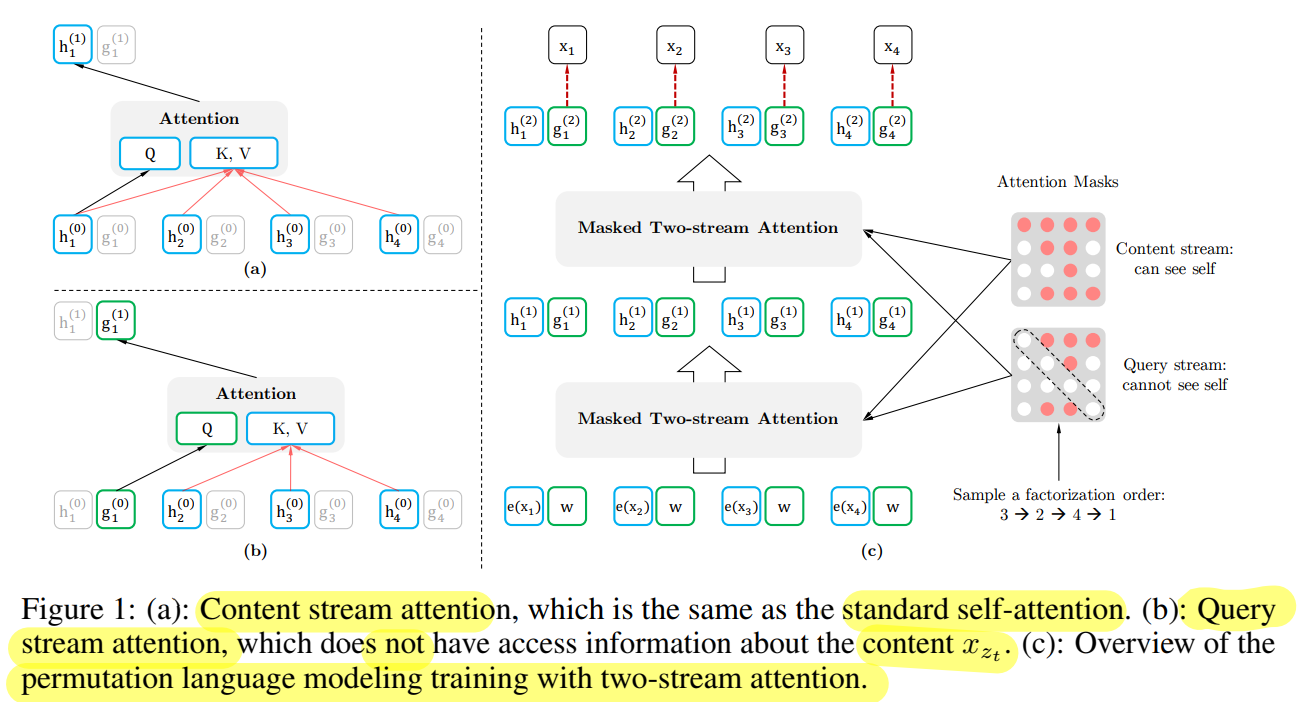
- 특정 시점 t에서 target position zt 의 token xzt을 예측하기 위해, hidden representation gθ(xz<t,zt) 는 t 위치 이전의 context 정보 xz<t와 t 위치의 target position 정보 zt 만을 이용해야 한다
- 특정 위치 t 의 hθ(xz≤t) 는 t 위치까지의 문맥과, xzt 자체에 대한 인코딩도 포함해야한다.
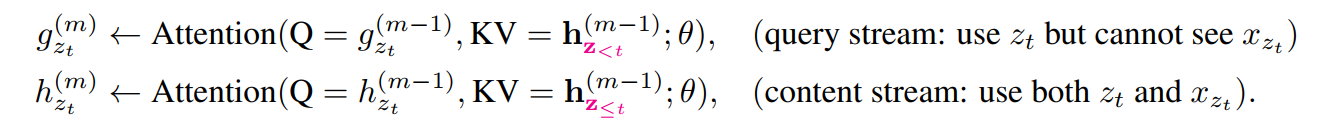
Partial Prediction
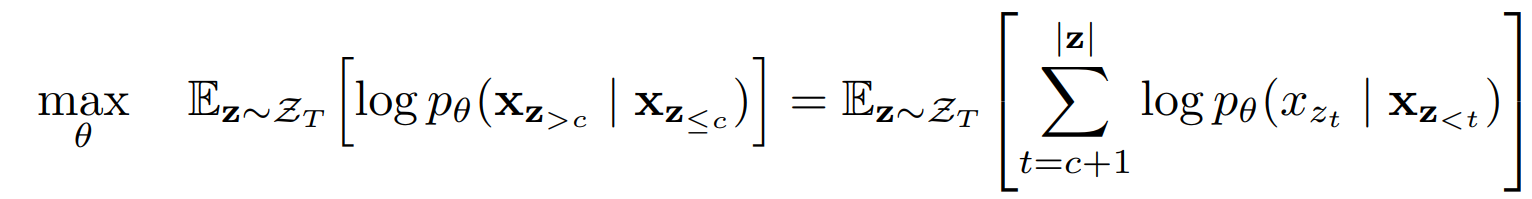
permutation language modeling 을 통한 objective 에서 모든 단어를 예측하는 것은 너무나 어려운 일이기에 최적화가 쉽게 일어나지 않는다.
따라서 새로운 permutation 으로 구성된 sequence의 일부분 (non-target subsequence)을 가지고 작은 부분(target subsequence)만을 예측하도록 하는 task로 수정하게 되었다. 두 부분이 나뉘는 경계를 cutting-point (c) 라고 한다.
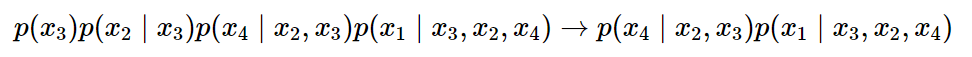
2.4 Incorporating Ideas from Transformer-XL
The segment recurrence mechanism (Transformer-XL)

Transformer-XL 에서의 Segment-Level Recurrence 방식을 그대로 사용한다.
현재 segment 에 대해 attention 을 계산할 때 이전 segment 에 대한 hidden state를 재사용하여 더 긴 문맥을 학습할 수 있다
다만 해당연산에서 이전 segment 의 hidden state에 대해서는 가중치 update가 되지 않도록 해야한다 (Stop Gradient, SG)
Transformer-XL 논문에서는, sτ, sτ+1 를 각각 이전 segment, 현재 segment로 표현하며, attention 계산까지의 수식을 다음과 같이 나타내고 있다.
Query 는 현재 segment 의 (n-1) layer에서의 hidden state, Key와 Value 는 (n-1) layer에서 이전 segment와 현재 segment 의 hidden state를 concat 한 vector 이다
즉 attention 계산에서, 현재 segment가 이전 segment까지 참조하며 representation 을 학습할 수 있음을 알 수 있다
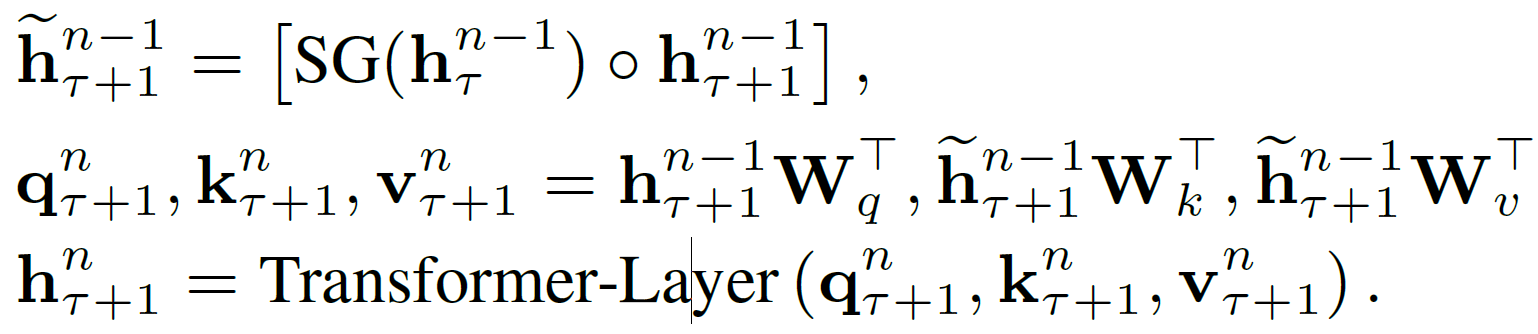
XLNet에서도 완전히 동일한 연산을 아래와 같이 나타내고 있다
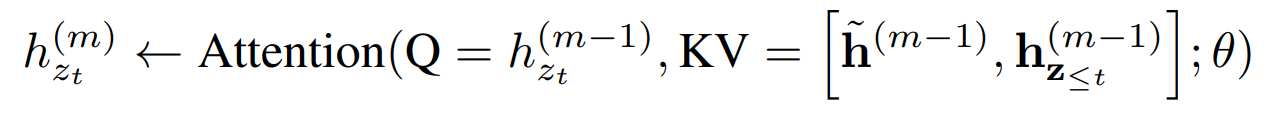
- ˜x:s1:T (이전 segment)
- ˜h: 이전 segment 의 연산 후 hidden state
- x:sT+1:2T (현재 segment) → ˜z, ˜h
해당 수식도, Query 는 현재 segment 의 (permutation z) hidden state이며, 즉 Key와 Value 는 아래 두 개의 concat인 것을 알 수 있다
- ˜h(m−1) : 이전 sequence의 representation
- hz≤t(m−1) : 현재 sequence의 permutation z 내에서 t 위치 이전까지의 문맥 representation
2.5 Modeling Multiple Segments
- 랜덤 두 개 segment concat 후 permutation language modeling 학습
- input 형식은 BERT와 동일한 X=[CLS,A,SEP,B,SEP]
Relative Segment Encoding 사용
위치정보를 유지하며 attention 계산을 수행하기 위한 positional encoding 방식으로, Transformer-XL에서와 같은 Relative Segment Encoding 을 사용한다
Relative Segment Encoding 은, 같은 segment 내에서 Key가 되는 기준 token (위치 i)과 Query token(위치 j) 간의 상대적 거리 (Ri−j)를 나타낸다
아래에서는 Transformer-XL 논문을 읽고, Relative segment encoding 에 대해 더 자세히 공부한 부분을 추가적으로 적어보았다.
Absolute positional encoding 의 문제점 (from Transformer-XL paper)
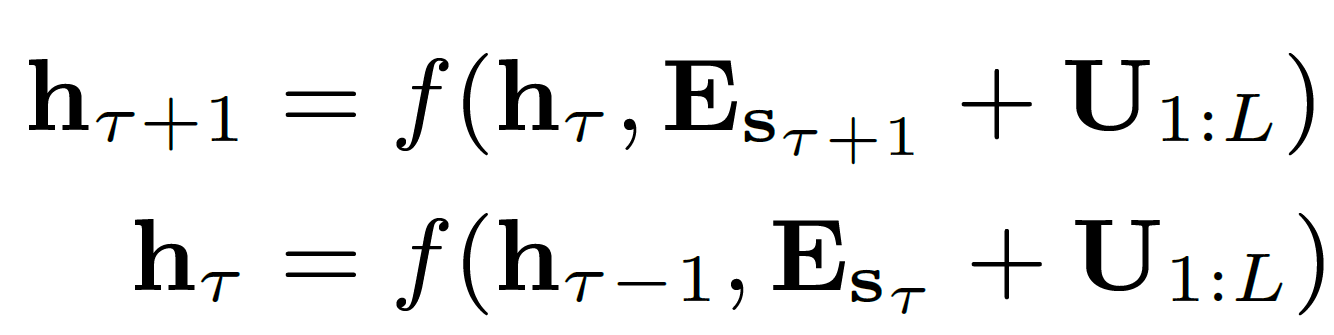
U∈RL: 기존 Tranformer에서의 positional encoding
절대적 위치를 반영하는 기존 positional encoding 을 사용할 경우, 이전 segment와 현재 segment 에서의 벡터 형태가 동일하다. 즉 사용하는 U 가 같은 것을 알 수 있다. 결국 모델 입장에서는 학습 시, 두 문장에서 같은 position 을 나타내는 토큰이 두 개로 인식하므로, 정확한 위치정보를 학습하지 못해 성능 감소로 이어질 수 있다.
이를 해결하기 위해 자세히 생각해보면, attention 계산에 활용되는 key token들의 절대적 위치를 알 필요가 없다. 따라서 Transformer-XL에서는 새로운 방법으로 이를 대체하는데, query 바뀔 때마다 각 key에 query 토큰과의 상대적 위치를 계산해서 정보위치를 반영하는 relative position encoding을 사용한다. 이와 함께, attention 연산에서 몇가지를 수정하였다.
Relative Segment Encoding 사용
지금부터는 Transformer XL에서 소개한, relative position encoding을 포함하며 수정된 Attention score 계산 연산을 살펴보자
먼저, 기존 Transformer 에서 토큰 i 와 j 간에 Attention score를 구하기 위한 연산을 살펴보면 다음과 같다. embedding vector 와 positional encoding (절대적위치) 을 더한 representation 에 Attention 연산을 수행한 것이다.
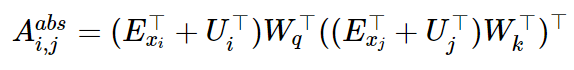
이를 전개하면 다음과 같이 표현 가능하다
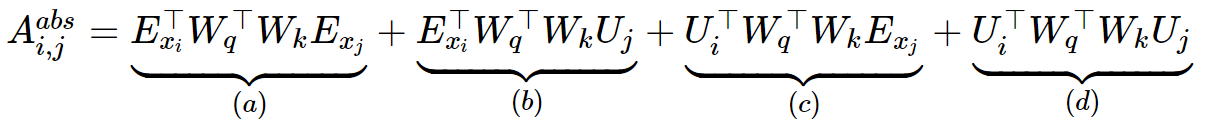
위의 식을 Transformer-XL에서는 아래와 같이 수정하였다
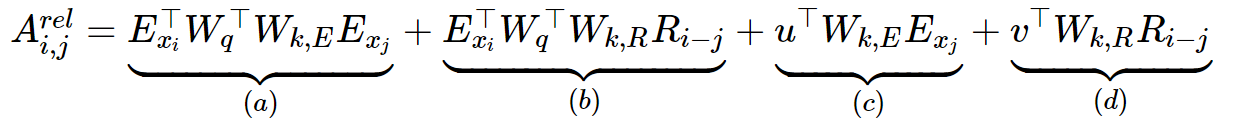
수정된 사항을 살펴보자
- (b), (d)에서 Key의 절대 위치정보를 나타내는 Uj 를 상대 위치정보를 나타내는 Ri−j로 대체하였다. 즉 Query 와 연산을 수행하는 Key 들의 위치정보로써 Query 와의 상대적 위치를 사용한 것이다
- Query 와 연산을 수행하는 Ui 에 대해서도 수정이 필요하다. (a), (c)에서는 Query 의 위치정보를 유지하는 것이 아니라, global 하게 일정한 bias 로 사용할 수 있는 learnable parameter 인 u,v∈Rd 로 대체했다
- (a), (b), (c), (d) 의 Key weight (WK) 를 의미를 담당하는 content (Wk,E)와 위치를 담당하는 position weight (Wk,R) 로 2개로 분리하였다. 이는 학습 시, content와 position 정보 간에 다양한 의존관계를 학습하겠다는 것으로 이해할 수 있다.
마지막으로, 학습 파라미터인 WK 기준으로 각 term 을 이해하면, 학습 시 각 term 의 역할을 이해할 수 있다. WK 기준으로 앞에서 뒤를 projection 하는 의존관계를 학습한다고 이해해보자
- (a) : (content → content), query에서 key로의 컨텐츠(의미) 전달(content-based addressing)
- (b) : (content → position), query의 의미 기반 key의 위치정보 (content dependent positional bias)
- (c) : (global bias → content), 문맥 내 key 의미 학습 (global content bias)
- (d) : (global bias → position), 문맥 내 key 위치정보 학습 (global positional bias)
2.6 Discussion
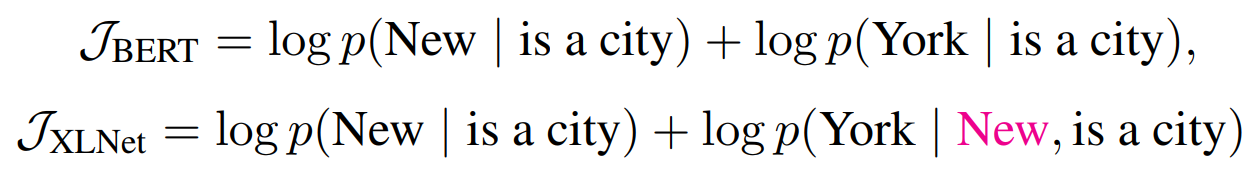
XLNet, BERT는 둘다 partial prediction 을 수행한다. 일부만을 예측에 사용함으로써,
- 충분한 길이의 sequence의 subset을 문맥에 활용하여, 의미있는 예측이 수행되도록 하고
- 모델이 Optimization 을 좀 더 수월하게 수행하도록 한다
3. Experiments
3.1 Pretraining and Implementation
BERT
- BooksCorpus + English Wikipedia (13GB text)
XLNet
- BooksCorpus + English Wikipedia (13GB text)
- Giga5 (16GB) + ClueWeb 20212-B (19GB) + Common Crawl (110GB)
- Sentencepiece : 32.89B subwords
XLNet-Large (= BERT-Large)
- max_len = 512, 8192 batch
- 5.5 days (512 TPU v3) 500K, Adam weight decay, linear learning rate decay
- bidirectional data input pipeline (forward : backward = 5:5)
- K = 6
- span based prediction
3.2 Fair Comparison with BERT
SQuAD, GLUE Dataset

- XLNet > BERT
- 두 모델 간 같은 데이터 및 하이퍼파라미터 사용, 유의미한 성능격차
3.3 Comparison with RoBERTa
Reading Comprehension (RACE), Document ranking task (ClueWeb09-B)
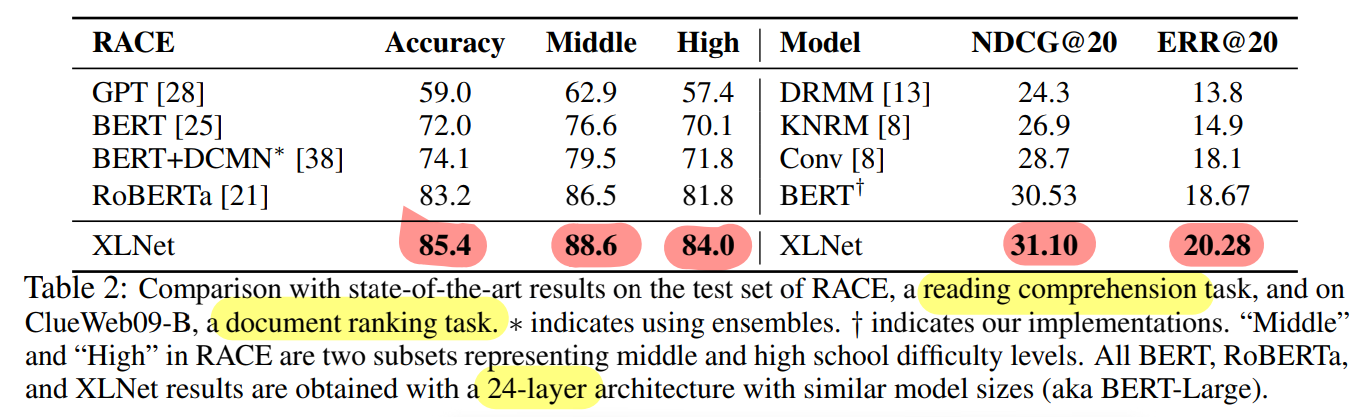
- XLNet > RoBERTa, BERT
- XLNet 발표 이후에 RoBERTa 와 ALBERT 등장, ALBERT는 많은 연산을 요구하여 비교불가
- 단일모델인 XLNet 이 Ensemble 기반의 BERT모델과 RoBERTa 보다 우세한 성능을 보인다
Question Answering (SQuAD)
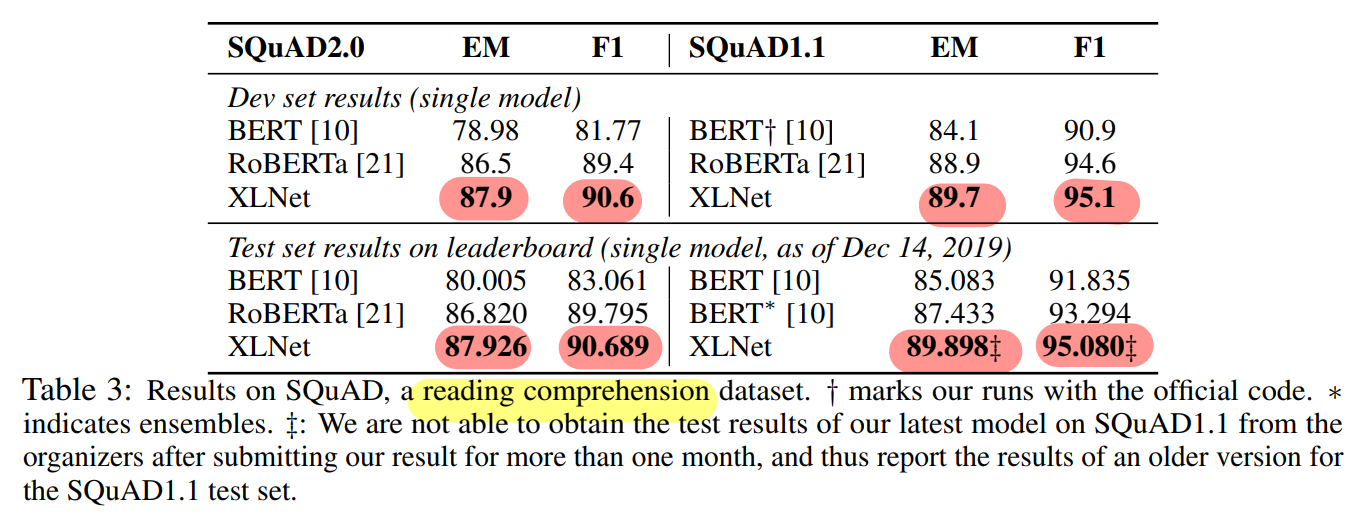
- XLNet > BERT, RoBERTa (Dev set, public LB)
Text Classification
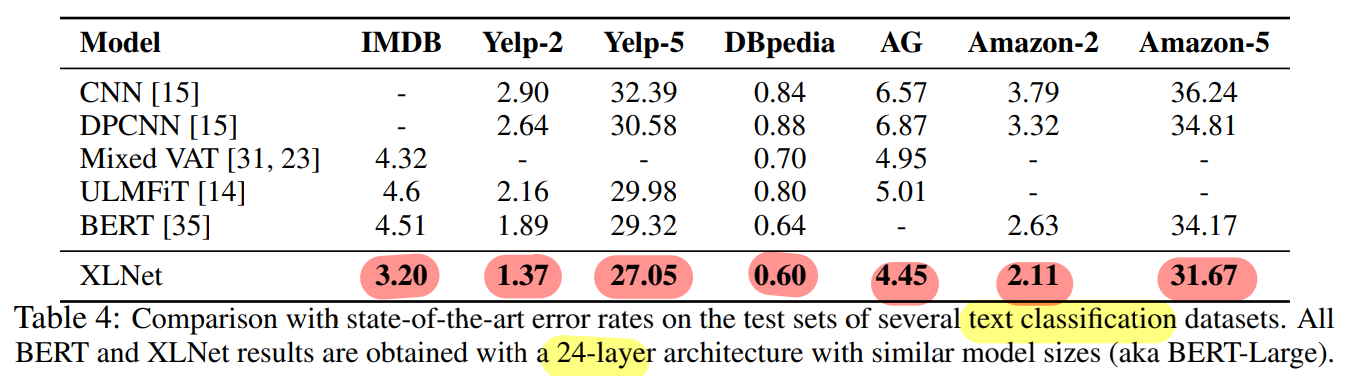
- XLNet (SOTA)
GLUE
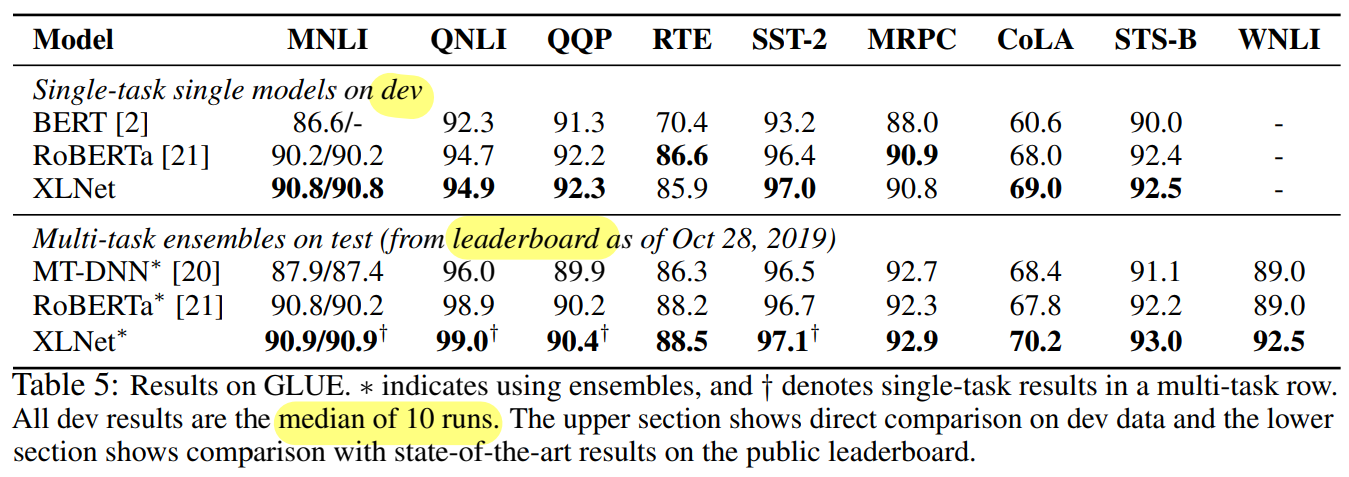
- XLNet (SOTA)
특이사항
- 긴 문장들을 가진 SQuAD, RACE 에서 Transformer-XL 기반의 XLNet의 성능우세 정도 증가
- 데이터가 큰 경우, XLNet 의 성능우세 정도 증가
3.4 Ablation Study
- permutation language modeling 의 효과 (vs denoising auto-encoding : masking)
- Tranformer-XL 구조의 효과
- span-based prediction, bidirectional input pipeline, next-sentence prediction 사용의 효과
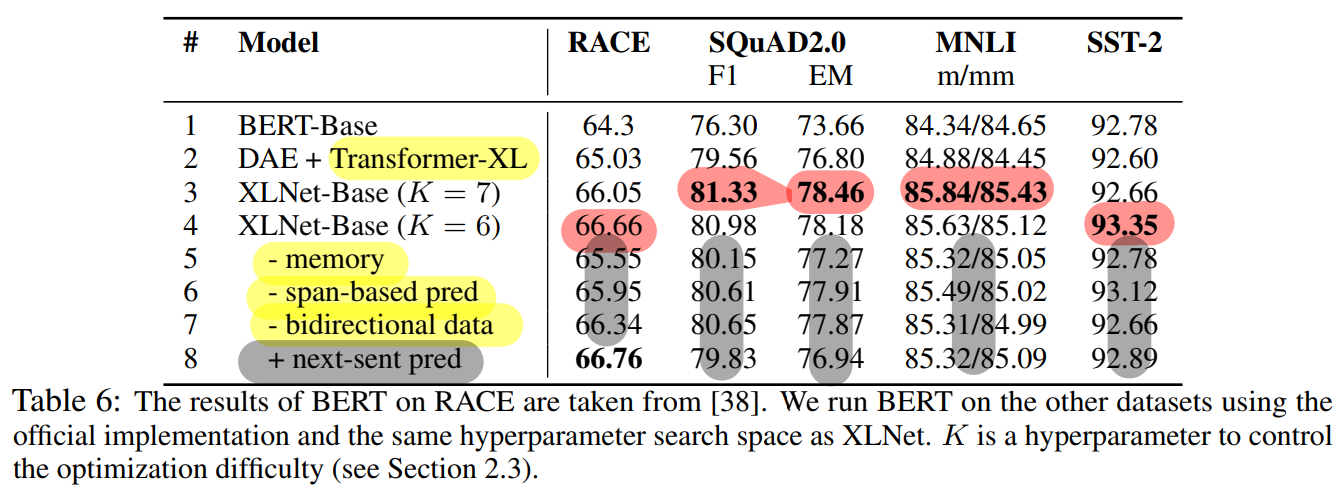
- 12 layer, 하이퍼파라미터 사용 통일, Wikipedia + BooksCorpus (= BERT-base)
- 성능기록 : median of 5 run
- #2 ↔ #1 : Transformer-XL 효과 확인 (2 > 1)
- #3, #4 ↔ #2 : Permutation language modeling 효과 확인 (3, 4 > 2)
- #3, #4 ↔
- #5 : memory 사용 시 성능 증가(+)
- #6 : span-based prediction 사용 시 성능 증가(+)
- #7 : bidirectional input data pipeline 사용 시 성능 증가(+)
- #8 : next-sentence prediction 사용 시 성능 감소(-)
4. Conclusions
- XLNet 은 permutation language modeling 을 사용함으로써, AR 및 AE 의 장점을 모두 가지게 되었다
- pre-train 과 fine-tune 사이의 discrepancy 를 해소하고 (AR)
- bidirectional 한 context 를 학습하게 되었으며 (AE)
- 예측된 token 들에 대해서도 나머지 token들과의 의존성을 학습할 수 있게 되었다. (AR)
- 또한 Transformer-XL 구조와 two-stream attention 을 사용함으로써, target position 에 대한 모호성도 해결하여 학습의 효과성이 향상되었다.
- 이러한 XLNet은 fine-tuning 시, 여러 task에서 SOTA를 달성할 수 있었다
스터디원들과의 QnA 및 Discussion
Q. slow convergence 의 의미? (partial prediction 을 사용한 이유)
A. 여러 permuatation 에 대해 모두 naive 한 language modeling 을 수행할 수 있도록 모델을 학습할 경우, 학습 난이도가 높아 모델의 loss 수렴 수월하지 않을 수 있는데 slow convergence 란 이러한 현상을 가리킨 것으로 보인다.
따라서, XLNet은 모든 permutation z 마다 일정한 길이의 문맥을 항상 주고, 해당 문맥이 주어질 때 이후 span 을 예측하는 partial prediction 형태의 language modeling 을 통해 학습하는 것으로 수정했다고 이해할 수 있다. (최적화를 위한 objective 난이도 수정)
Q. 아래 수식의 정확한 의미?
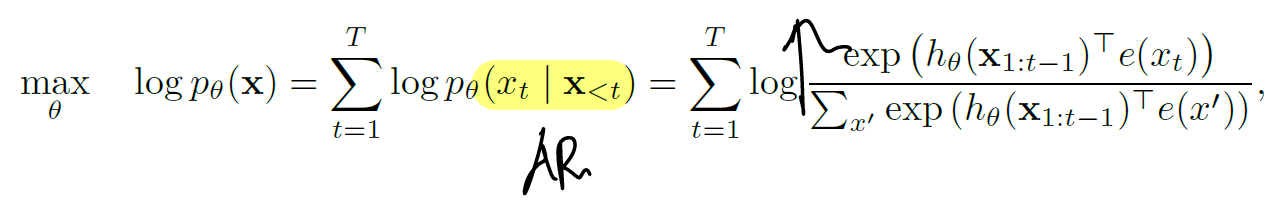
A. AutoRegressive objective (AR)라고도 불리는 일반적인 language modeling objective 이다. t 위치의 토큰 (x_t) 을 예측하기 위해 이전 토큰들의 representation 을 input으로 사용한다. 모델 연산 결과인 hidden state (h_{\theta}) 에 대해, embedding layer와 softmax 연산을 수행하여 정답 토큰 (x_t) 을 올바르게 예측하도록 학습하며 모델 parameter \theta 를 얻는다
<Reference>
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860.
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. R., & Le, Q. V. (2019). Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32.
https://blog.pingpong.us/xlnet-review/
https://baekyeongmin.github.io/paper-review/transformer-xl-review/





댓글 영역