고정 헤더 영역
상세 컨텐츠
본문
RoBERTa: A Robustly Optimized BERT Pretraining Approach 논문 리뷰
Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다
<RoBERTa 한줄요약>
선행연구에서 보여주었던, BERT와 관련된 사전학습 방식 및 Input Sequence 설계, 하이퍼파라미터들의 성능 향상효과를 검증하고, 이를 바탕으로 최적의 모델인 RoBERTa를 제시하였다.
<시작하기 전, 간단한 리뷰 후기>
RoBERTa 또한 GPT-2에 이어 연구 접근방식이 남다른 논문이라고 생각되었다. 기존 프레임 안에서, 새로운 objective를 제시하거나 하지않고, 앞선 선행연구들의 성능향상 요소를 모두 결합하여, 효과를 검증하고 최적화를 시도한 것이다.
RoBERTa를 읽으며 떠오르는 논문이 2가지가 있었는데, Image Classsification 에서의 EfficientNet 논문과 Detection 에서의 YoloV3 논문이다. EfficientNet의 경우, 성능 최적화를 위한 하이퍼파라미터 조합을 탐색하고, 이를 바탕으로 최적화된 모델을 제시하였고, YoloV3는 기존에 Dectection 선행연구들에서 소개되었던 방법들을 모두 하나씩 더하며 성능향상을 이끌어냈다. 논문들을 읽다보면, Domain-Cross하게 영향을 주는 모습을 종종 보는데, RoBERTa 또한 Vision에서의 Approach에서 간접적으로 영향을 받은 것이 아닐까하고 생각해보게 되었다. 그리고, NLP 외에도 DL의 다른 Domain 논문을 읽거나 Trend에 관심을 가지는 것 또한 연구자에게 있어 연구를 지속할 수 있는 좋은 방법이라는 생각이 들었다.
Abstract

- BERT의 사전학습에서 중요한 하이퍼파라미터들과 데이터 사이즈과 성능 간 관계 실험
- RoBERTa : GLUE, RACE, SQuAD 에서 SOTA
1. Introduction
- 여러 언어모델 등장에도 불구하고, 정확히 어떤 면이 성능향상에 기여했는지 분석이 어렵다
- 많은 연산량 → 한정된 시간
- 비공개 학습데이터
- 따라서, BERT의 하이퍼파라미터 및 학습 데이터 사이즈 선택에 따른 효과를 검증한다 → 결론 도출 (RoBERTa)
- Train model the longer with bigger batches on more data (더 많은 데이터에 대해 큰 배치사이즈로 더 오래 학습)
- Remove next sentence prediction objective : NSP 제거
- Train on longer sequences : 긴 문장의 형태로 학습
- dynamic masking pattern : 10 epoch마다 동일한 example에 대해 masking 변형
- RoBERTa는 GLUE의 4/9 (MNLI, QNLI, RTE, STS-B)와, SQuAD 및 RACE에서도 SOTA 달성
- RoBERTa 의 Contributions
- BERT의 효과적인 학습 방식 제시
- 새로운 데이터(CC-NEWS)를 사용하고, 더 많은 데이터의 성능 견인을 확인
- 최근 다른 objective를 사용한 모델보다 높은 성능을 통해 MLM의 우수성 재확인
2. Background
BERT 에 대한 자세한 내용은, 이전 Review 에서 확인 가능!
(BERT) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰 (feat. SQuAD fine-tuning Code)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰 Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다 Abstract Deep b..
matthew0633.tistory.com
2.1 Setup
- $X=[CLS], x_1,...,x_N, [SEP], y_1,...,y_M,[EOS]$
- $N + M < T\:(max\_seq\_len)$
2.2 Architecture
- Transformer Encoder 사용
- $L : num\_layers$
- $A : self\_attention\_head$
- $H : Hidden\_dimension$
2.3 Training Objectives
- Masked Language Model (MLM) + Next Sentence Prediction (NSP)
2.4 optimization
- Adam
- Linear warmup and decay (10,000 step for $lr_{max} = 1e-4$ )
- Dropout (0.1); GeLU
- Pre-train with 1M Steps (BS = 256, T = 512)
2.5 Data
- BOOKCORPUS + English WIKIPEDIA (16GB total)
3. Experimental Setup
3.1 Implementation
- warmup step, peak LR은 setting마다 조정 (다른 것은 기존 BERT와 동일)
- Adam ($\beta_2 = 0.98$) for large batch size
- T = 512 (max seq len)
- 모든 step에서 최대길이의 긴 문장으로 학습
- mixed precision floating point 사용
3.2 Data
- BOOKCORPUS (16GB)
- CC-NEWS (76GB) : Common Crawl news 의 일부
- OPENWEBTEXT (38GB) : Reddit 데이터로, GPT-2 데이터 재현
- STORIES (31GB) : Common Crawl 에서 스토리형식의 텍스트
3.3 Evaluation
- GLUE
- dev-set에 대한 결과는 single-task training을 사용하여 성능 측정
- test-set(LB)에 대한 결과는 task-specific modification 사용한 성능 측정
- SQuAD
- joint objective 사용 : classification loss + span loss
- binary classification : if answerable or not
- span prediction : span indices if answerable
- joint objective 사용 : classification loss + span loss
- RACE
- 대량의 기계독해 데이터 : 4지선다형 (긴 지문에 의해 높은 난이도)
4. Training Procedure Analysis
- BERT-BASE (L =12, H = 768, A = 12, 110M params) 사용
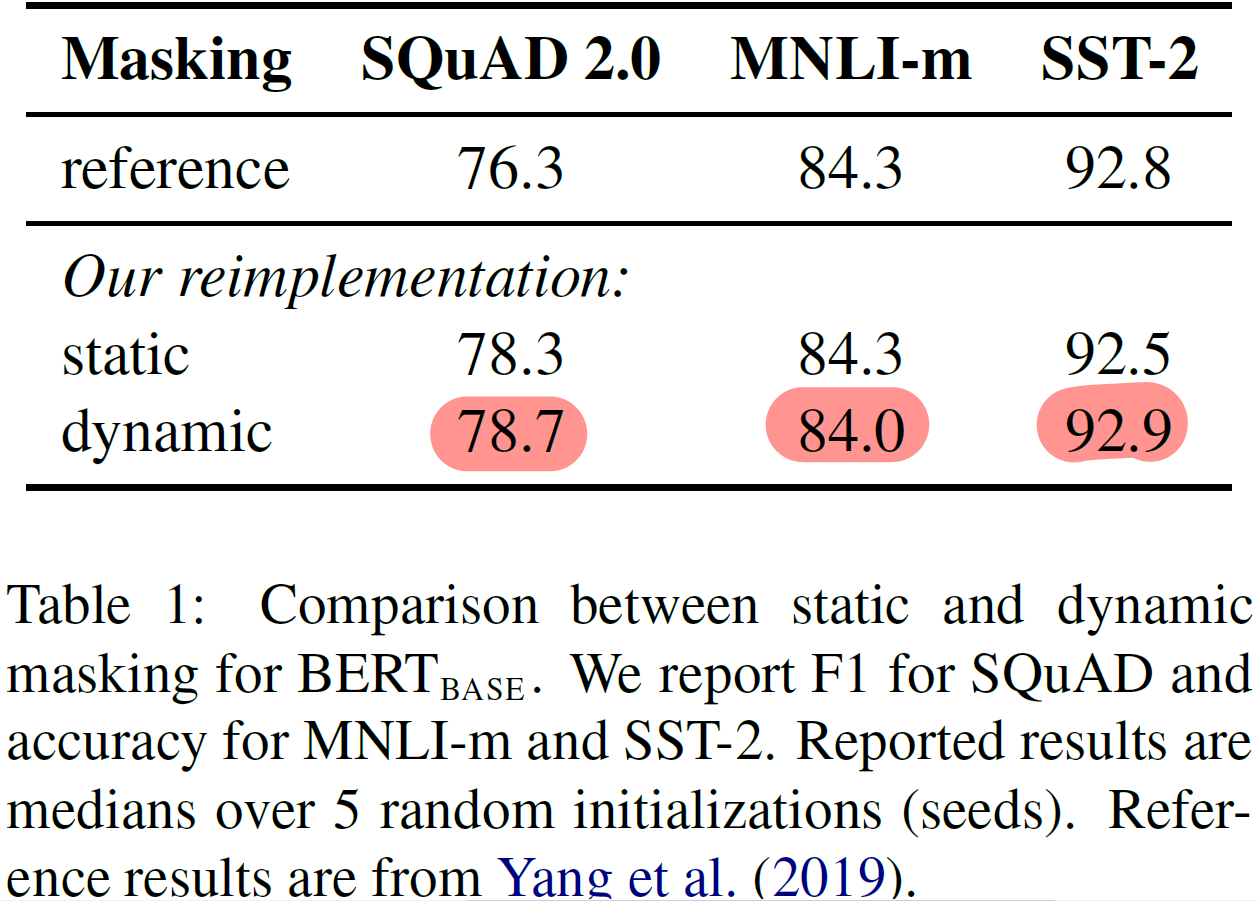
4.1 Static vs Dynamic Masking
- Static Masking
- 기존 BERT의 방식으로, 전처리에서 masking 적용 후 학습 시 패턴 고정; 매 epoch마다 동일한 mask 를 보게된다
- Dynamic Masking
- 4 epoch마다 동일한 example 기준으로, mask 패턴을 변형해준다. 즉, 40 epoch 동안 동일한 example에 대해 같은 패턴을 4번만 학습하며, 40 epoch 동안 해당 example 에 대해 10개의 다른 masking 패턴을 학습하게 된다
- Results
4.2 Model Input Format and Next Sentence Prediction
- NSP 효과에 대한 선행연구들의 상반된 의견 → 테스트 시도
- segment-pair + NSP
- sentence-pair + NSP
- full-sentences (NSP X):
- 동일 문서 또는 다른 문서까지 여러 연속된 문장을 input으로 사용
- 다른 문서에 속한 문장 전에 [SEP]로 구분
- doc-sentences (NSP X):
- 동일 문서에 한해서 여러 연속된 문장 사용
- 그러나 문서 끝부분에 가까울수록 학습에 사용되는 토큰 수가 적기에, 이 때는 배치사이즈를 늘린다 (배치사이즈의 유연한 조정 필요)
- Results
- 대체로, NSP를 사용하지 않은 방법이 나은 성능
- segment-pair > sentence-pair : 단일 문장 사용 시, 긴 문맥 학습효과 저하 (sentence-pair)
- doc-sentences > full-sentences : 같은 문서 내에 속한 문장들로 input을 구성했을 때 더 나은 결과, 그러나 배치사이즈 조정이 필요하기에 이후 실험에서는 full-sentences 방법 사용

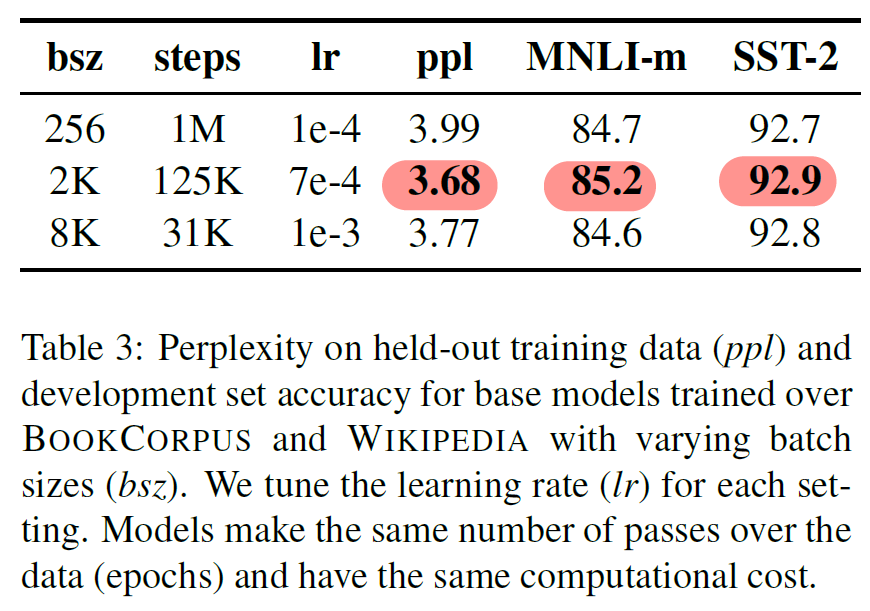
4.3 Training with large batches
- 기계번역과 BERT 관련 선행연구에서 대량의 batch 사용 시, 수렴속도 증가와 성능 증가 사례를 확인했다 (BS = 32K 사용 연구도 존재)
- Results
- MLM의 Perplexity 향상
- 모델의 Accuracy 성능 향상
- 수렴 속도 향상 (125K vs 1M steps)
- 데이터 분산학습 사용이 수월하므로, 이후 실험에서 BS = 8K 사용
4.4 Text Encoding
- Byte-Pair Encoding (BPE) : Hybrid of character, word level representation
- 기존 BERT에서는 character-level의 30K vocab 사용
- 본 연구에서는 GPT-2 가 사용한 BPE에 따라 subword-level의 50K vocab 사용
- 이에 따라, BERT-BASE, BERT-LARGE 에서 각각 15M, 20M의 파라미터 수 증가
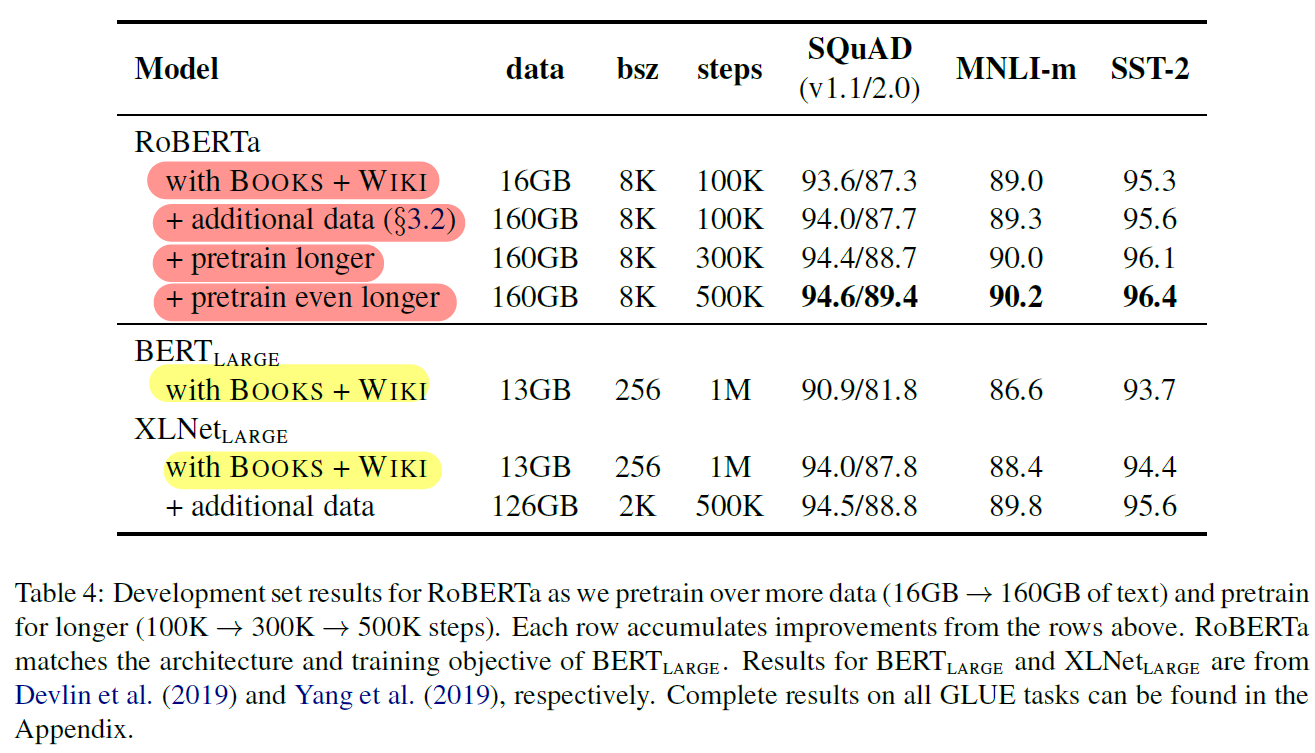
5. RoBERTa
- RoBERTa : Robustly optimized BERT Approach
- dynamic masking
- full-sentences pair (NSP X)
- Large mini-batch
- Larger byte-level BPE
- Larger Data
- Longer Steps
- Results
- 같은 데이터 (BOOKS + WIKI) 학습 시, RoBERTa가 우세
- 학습 데이터 추가 시 성능향상
- 학습 시간 증가 시 성능 향상 : 100K → 300K → 500K
5.1 GLUE Results
- (single-task, dev) setting
- $BS \in \{16, 32\}$
- $LR \in \{1e-5, 2e-5, 3e-5 \}$
- 10 epochs, linear warmup and linear decay(6% steps, decay to 0), early-stopping
- median dev-set score with 5 random init.
- (ensembles, test) setting
- single-task finetuning
- RTE, STS, MRPC : MNLI single-task 선 학습
- Task-specific modifications
- QNLI : (question, candidate) → T/F
- WNLI
- margin ranking loss 사용
- noun phrases (spacy) : positive scores > negative scores
- Results
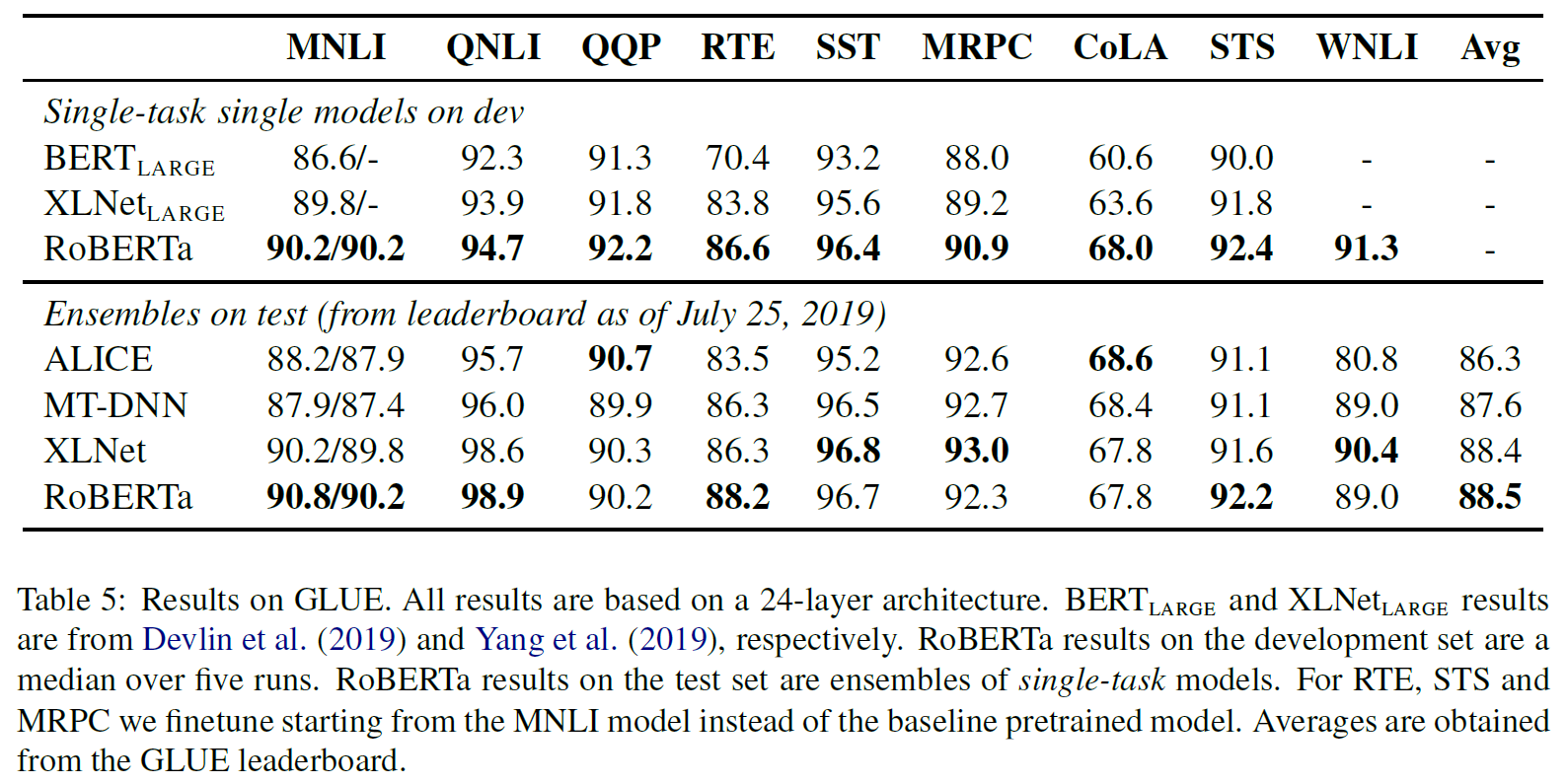
- (single-task, dev) 에서 9/9개 모두 SOTA 달성
- architecture나 train objective 수정이 아닌, data size, train time 만으로 성능 향상
- (ensembles, test) 에서 4/9개 SOTA 달성
- RoBERTa가 다른 모델들과 달리 multi-task learning을 사용하지 않았기 때문이다
- (single-task, dev) 에서 9/9개 모두 SOTA 달성
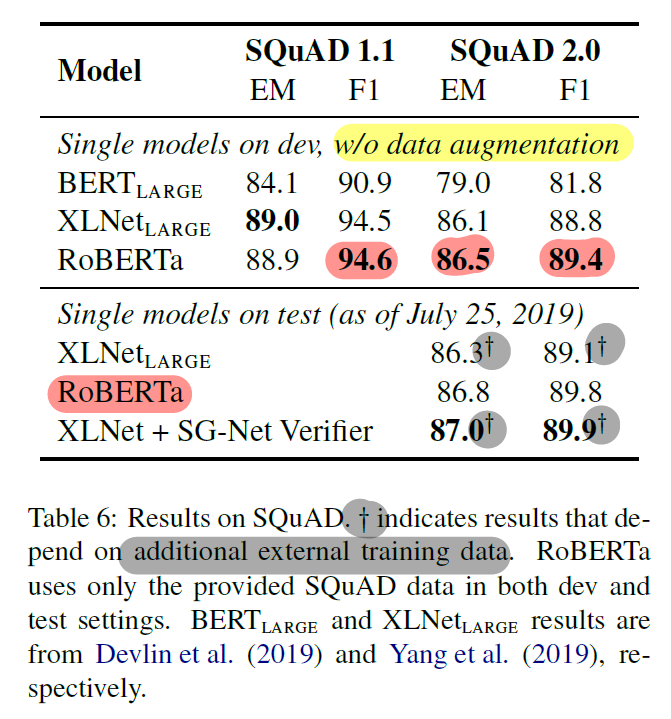
5.2 SQuAD Results
- BERT, XLNet과 달리 Data Augmentation을 사용하지 않았다
- XLNet과 달리 모든 layer에 일정한 LR 사용
- v2.0 에서는 answerable 에 대한 classification loss 를 joint 하게 사용하였다.
- Results
- v1.1 에서는 SOTA인 XLNet과 비슷했고, v2.0에서는 RoBERTa가 SOTA
- LB에서도 augmentation 없이 single model 로서 높은 성능 입증
5.3 RACE Results
- $[d;q;a_i] : True/False$ 형식의 Classfication task 사용
- question, answer pair 이 128보다 길 때, 지문 또한 지나치게 길 때 truncation 사용

6. Related Work
- Pre-train 에 대한 objective 연구가 지속되어 왔다
- Language Modeling
- Masked Language Modeling (MLM)
- variants of MLM
- 일부 연구들은 finetuning 방식이나, multi-task finetuning 방식 소개한다
- entity embedding, span prediction, variants of autoregressive pretraining
- 더 큰 모델과 많은 데이터로 성능 향상을 보여준 연구도 존재한다
본 연구에서는 선행연구에서의 성능향상 요소들을 비교평가하고, 최적의 모델인 RoBERTa를 도출한다
7. Conclusion
BERT의 사전학습 방식 및 설계의 옵션들의 효과를 평가하고, 결과를 통해 다음 방식을 사용한 최적화된 BERT인 RoBERTa 를 제시한다.
- Dynamic masking
- Longer Sequences without NSP
- Large mini-batch
- Larger Data
- Longer Steps
RoBERTa는 multi-task learning이나 augmentation 없이 GLUE, RACE, SQuAD 에서 SOTA를 달성했다
스터디원들과의 QnA 및 Discussion
Q. segment-pair 과 sentence-pair 의 차이점은? 즉, segment 와 sentence 의 정확한 의미 및 차이는?
A.
"BERT의 sentence와 RoBERTa의 sentence 는 다른 의미이다"
먼저, sentence라는 용어의 의미에 대해 명확히 할 필요가 있다. 기존 BERT의 논문에서는, segment와 sentence 용어를 동일하게 "자연어에서의 문장에 해당하지 않는, 토큰 sequence"라는 의미로 혼용했다. 그러나, RoBERTa에서는 4.2에서 알 수 있듯, BERT가 input으로 사용하는 하나의 단위 ([SEP] 토큰으로 분리되는)가 segment라고 명확히 사용하고 있고, sentence-pair 라는 실험방식의 설명에서도 "sentence"가 natural sentence 라는 의미인 것으로 설명하고 있다.
"자연어 기준 완전한 문장을 이은 sentence-pair, batch size를 증가시키다"
따라서 RoBERTa에서 segment는 자연어에서의 완전한 문장을 이루든, 이루지 않든 토큰의 연속된 sequence를 의미하고, sentence는 토큰 시퀀스이지만, 해당 단위가 자연어에서의 완전한 문장에 해당되는 단위를 의미하고 있다. 특히 sentence-pair 방식에 대한 설명에서, 두 개의 완전한 문장으로 input sequence를 구성한다고 했을 때, segment-pair에 비해 길이가 확연이 짧아진다고 한다는 부분도, 이에 부합한다고 할 수 있다. 왜냐하면 자연어에서의 완전한 문장이 [SEP] 토큰 앞뒤를 이루는 단위가 된다면, 해당 문장이 짧다면 두문장을 잇더라도 길이가 짧아질 수 있기 때문이다. (이에 반해 segment는 완전한 문장 여부와 관계없이 일정한 길이를 채운 토큰 sequence 이다)
이러한 단점 때문에 학습 과정에서 모델이 볼 수 있는 문장(토큰의 수)들을 늘리고자, 배치사이즈를 늘리는 방법을 사용하여, 보완했다.
<Reference>
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692





댓글 영역