고정 헤더 영역
상세 컨텐츠
본문

SpanBERT: Improving Pre-training by Representing and Predicting Spans 논문 리뷰
Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다
<spanBERT 한줄요약>
기존의 BERT가 Individual token 단위의 MLM이였다면, spanBERT는 span 단위의 MLM, 그리고 span boundary 를 이용하여 MLM을 수행하는 두 objective를 사전학습에서 사용하여, 여러 토큰으로 이루어진 span 단위의 문맥 학습의 성능을 향상한 모델이다.
<시작하기 전, 간단한 리뷰 후기>
개인적으로, Ablation Study를 흥미롭게 읽었다. BERT로 시작된 MLM을 선행연구들에서 다양한 변형기법을 적용하여 사용해왔는데, 이들을 비교하여 span maksing의 우수성을 입증하였기 때문이다. 특히, 기존에 개체명이나, 언어구조 내 지식을 이용하여 문맥을 좀 더 효과적으로 학습하려는 접근은 GNN 과 NLP 도메인 간 결합으로 이어질 것 같아서 관심이 가게 되었다. 이후에 해당 연구에서 파생된 연구들을 읽어볼 계획이다.
Abstract

- BERT의 사전학습 방식인 MLM 을 수정하여 기존 BERT 대비 성능향상을 이루었다
- 사전학습 시, 연속적인 토큰들(span)에 대해 masking 한다
- mask 토큰을 예측하는데 span boundary 의 representation 을 활용하도록 학습한다
- span 단위의 downstream task 에서 두드러진 성능 향상을 보여주었다
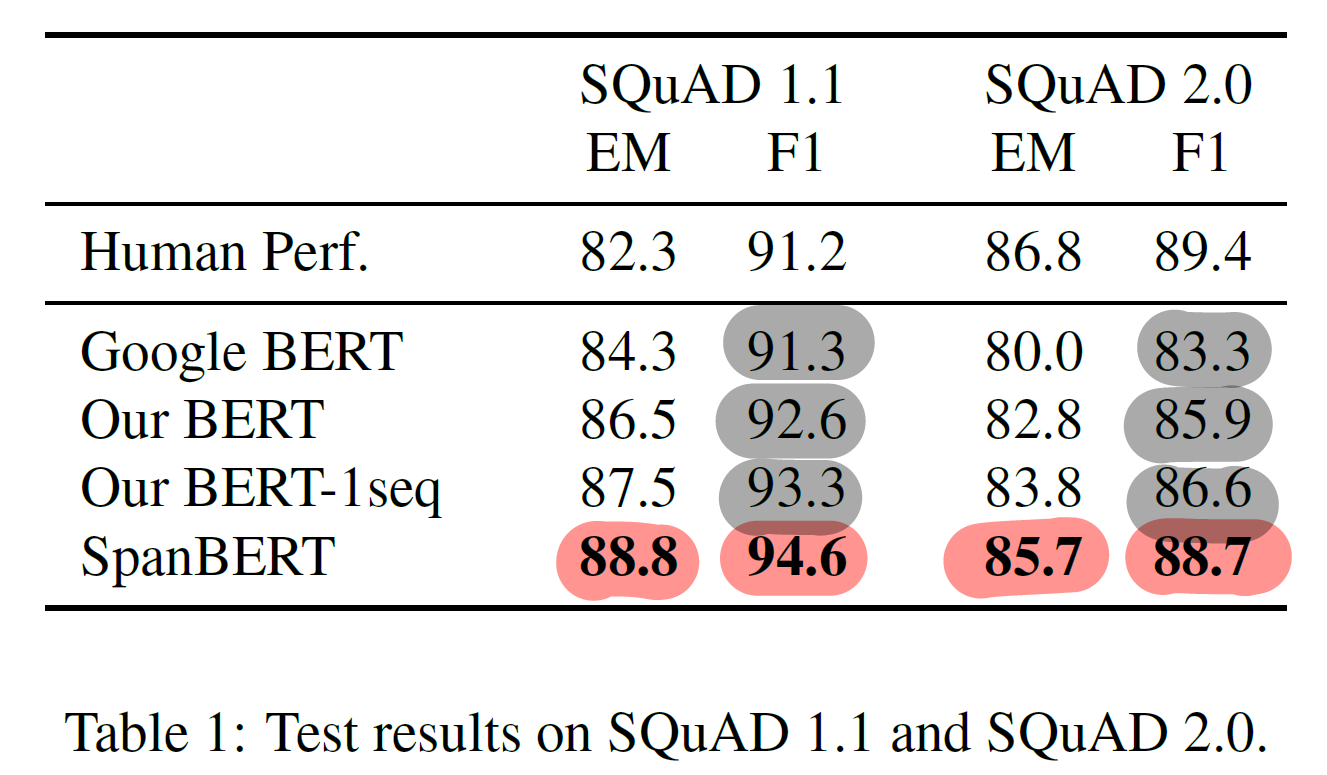
- Question Answering : SQuAD v1.0, v2.0 (F1 94.6%, 88.7%)
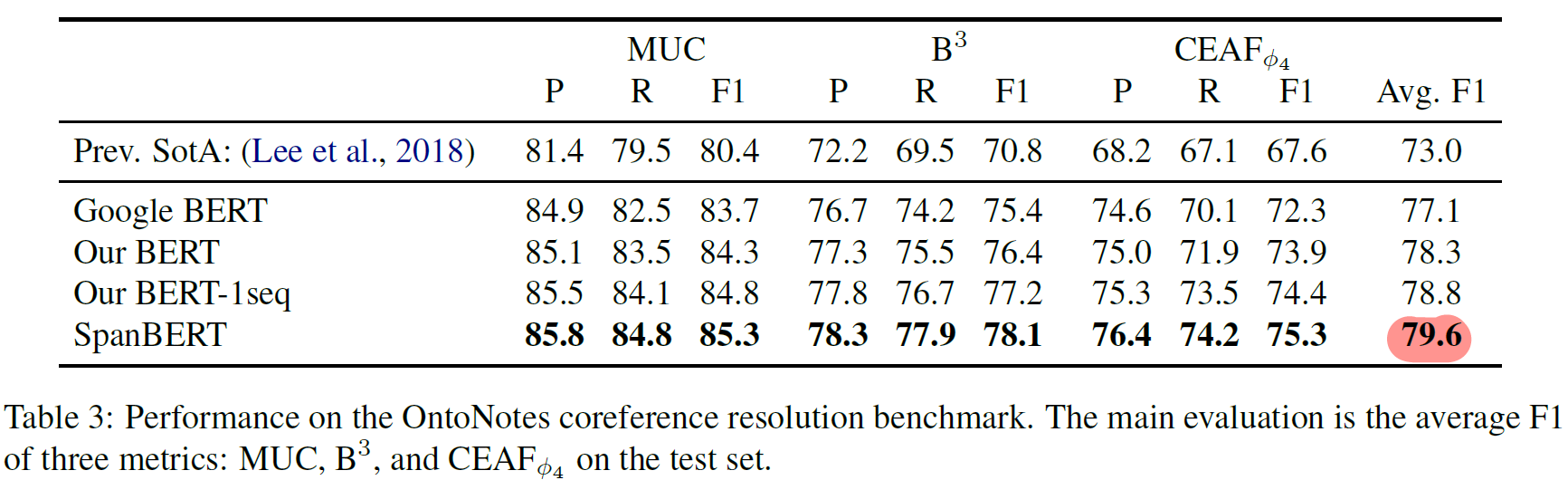
- coreference resolution : OneNotes (F1 79.6)
- Relation Extraction : TACRED
- Natural Language Understanding : GLUE
1. Instruction
연구배경
- self-supervised 학습(i.e. MLM) 을 이용한 Pre-training 모델 유행 중이다
- 2개 이상 토큰에 해당하는, span 단위의 관계 학습이 필요하다
- e.g. Which team won Super Bowl 50?” → “Denver Broncos” > “Denver”
- span 단위의 사전학습 방식 소개
- question answering, coreference resolution task에서 유의미한 성능향상
spanBERT
- 랜덤한 연속적인 토큰 (span)들을 masking (cf. BERT는 연속성이 없는 개별 토큰 masking)
- span-boundary objective (SBO) 활용한 예측 : span-level의 정보를 반영하는 representation 을 학습하도록 함
- NSP를 제거하고, 하나의 sequence 에 대해 학습 (cf. BERT는 최대길이 절반의 두개 문장을 활용하여 NSP objective 학습)
span-level task에서 큰 성능향상
- Extractive Question Answering
- SQuAD v1.1 (F1 94.6%)
- SQuAD v2.0 (F1 8.7%)
- NewsQA
- TriviaQA
- SearchQA
- HotpotQA
- Natural Questions
- Coreference Resolution
- “OntoNotes”(CoNLL-2012) : F1 79.6%(+6.6%), SOTA
데이터의 크기나 모델 사이즈 증가 없이, 사전학습 objective에 대한 수정만으로 성능향상을 보여준 것에 의미가 있다
2. Background
논문에서 해당 섹션에서 BERT에 대해 다루고 있으나, 이전에 BERT 논문을 리뷰한 것으로 대체한다
(BERT) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰 (feat. SQuAD fine-tuning Code)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰 Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다 Abstract Deep b..
matthew0633.tistory.com
3. Model
spanBERT : MLM + SBO
- MLM : Target token의 위치 i 에 대한 representation 으로 Target token (xi)을 예측하도록 학습
- SBO : span boundary representation과 위치 i의 position embedding 을 사용하여 Target token (xi)을 예측하도록 학습
- 랜덤한 연속적인 토큰들인 span을 masking
- cf. BERT는 연속성이 없는 개별 토큰 masking
- span-boundary objective (SBO) 활용한 예측
- span-level의 정보를 반영하는 representation 을 학습하도록 함
- NSP를 제거하고, 하나의 sequence 에 대해 학습
- cf. BERT는 최대길이 절반의 두개 문장을 활용하여 NSP objective 학습)
3.1 Span Masking
1) Length sampling
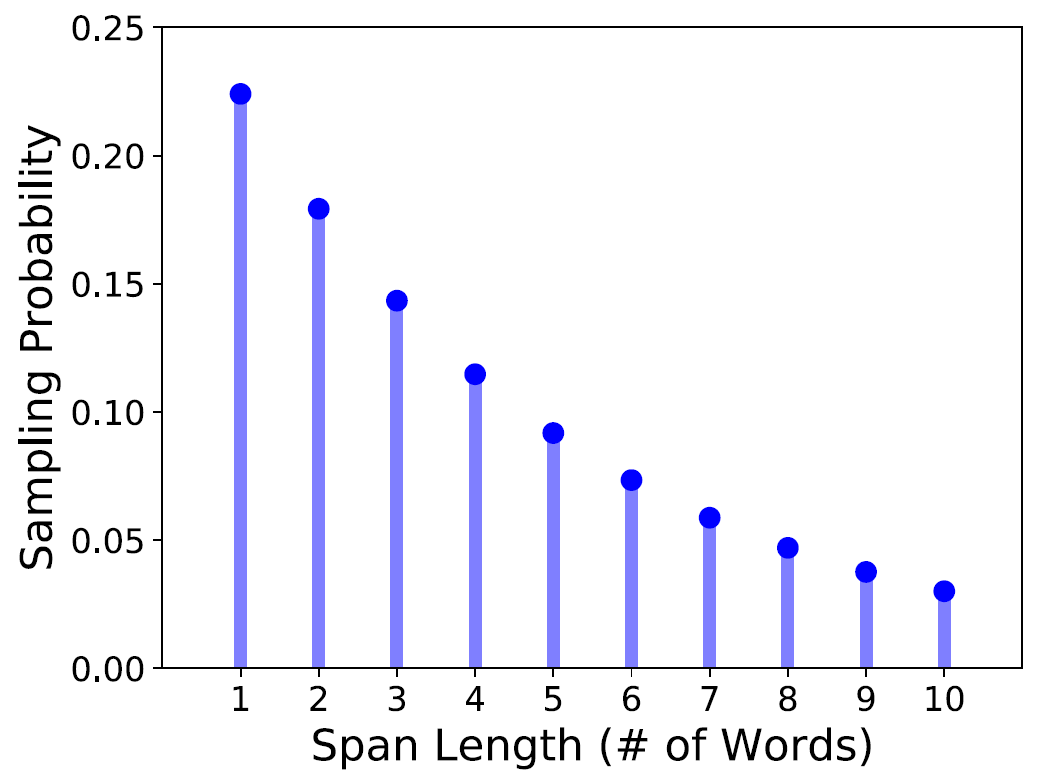
- len ~ Geo(p=0.2) : sampling with Geometric distribution
- lenmax=10 : 최대 span 길이 10으로 clipping
- mean(len) = 3.8 : 기댓값은 3.8
# fairseq/data/masking.py -> PairWithSpanMaskingScheme(MaskingScheme)
class PairWithSpanMaskingScheme(MaskingScheme):
...
def __init__(self, args, tokens, pad, mask_id, paragraph_info):
self.p = args.geometric_p # 하이퍼파라미터
self.len_distrib = [self.p * (1-self.p)**(i - self.lower) for i in range(self.lower, self.upper + 1)] if self.p >= 0 else None
self.len_distrib = [x / (sum(self.len_distrib)) for x in self.len_distrib]
def mask(self, sentence, tagmap=None)):
...
while len(mask) < mask_num:
span_len = np.random.choice(self.lens, p=self.len_distrib) # span length sampling (geometric dist.)2) Start point sampling
- uniform distribution
- 완전한 word 단위로 sampling
- sampling 된 word가 시작하는 token으로 설정
3) Span-level 의 8:1:1 strategy
- BERT와 달리 8:1:1 (masking, 유지, 랜덤토큰대체) 전략을 span 단위로 일관되게 적용
3.2 Span Boundary Objective (SBO)
Target token인 xi를 span boundary token 의 representation으로 예측하도록 학습한다
- span 에 해당하는 내용을 최대한 반영하는 representation을 얻는 것을 목표
- external boundary token 의 Representation 사용
- Left boundary : span의 처음 토큰(xs세)의 이전 토큰인 xs−1
- Right boundary : span의 마지막 토큰(xs) 이후 토큰인 xe+1
- target token 의 position embedding 인 pi−s+1 또한 사용한다
- span의 시작 토큰과의 상대적 거리를 나타내며, span 내에서 target token의 위치정보를 포함한다
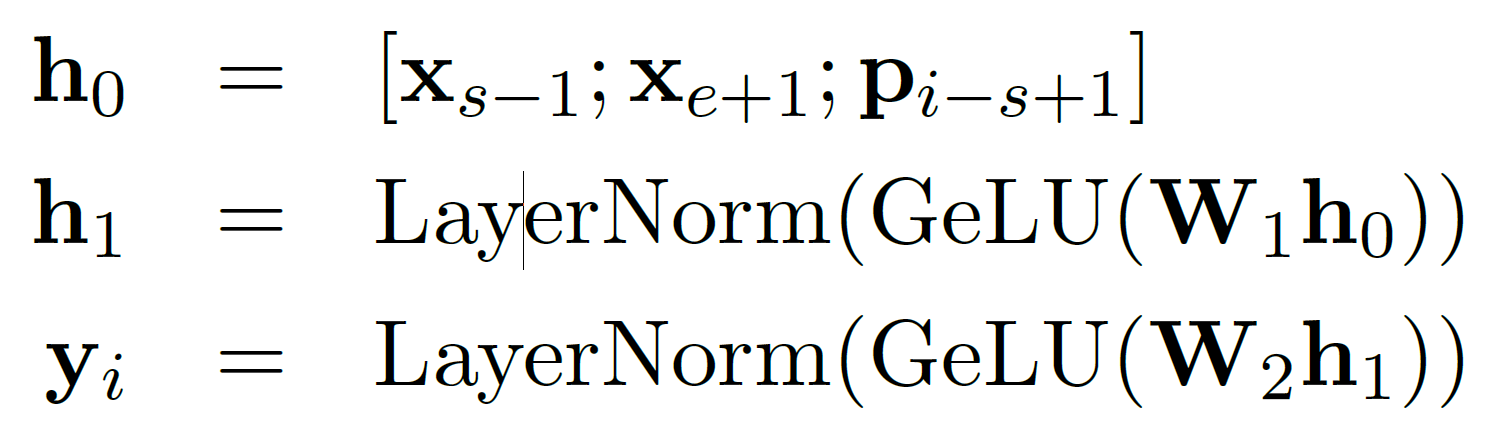
h0: xs−1, xe+1 의 representation 과 pi−s+1 을 concat
yi: h0 에 대해 2개의 FeedForwardNetwork layer 연산과 GeLU, LayerNormalization 연산 수행 결과
yi를 얻기 위한 연산을 f로 나타내면 아래와 같다
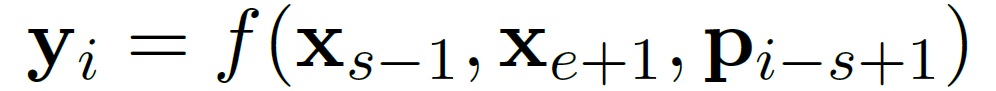
즉, y_i로 Target 토큰인 x_i 를 예측하는 objective가 SBO이다. 이를 수식으로 나타내면 아래와 같다

사전학습의 main objective 인 MLM과 auxiliary objective인 SBO를 함께 수식으로 나타낸 최종 pre-train objective는 다음과 같다
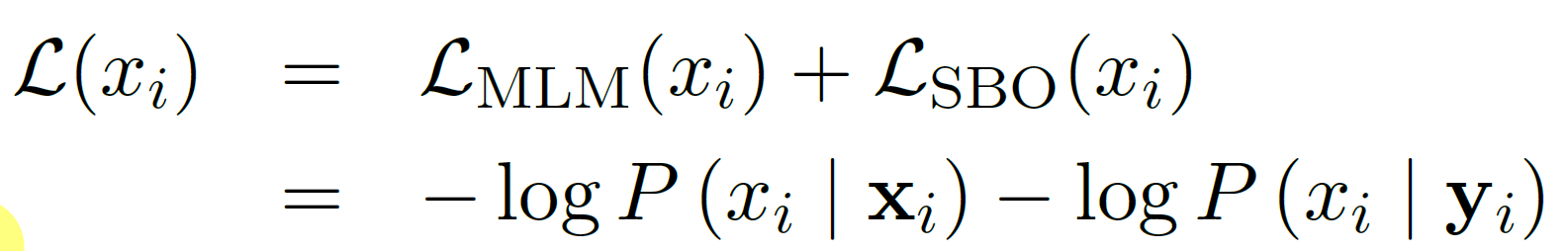
3.3 Single-Sequence Training
NSP : ifXA,XBiscontinuous
결과적으로 대부분 single sequence 로 학습한 것이 bi-sequence with NSP 방식으로 학습한 결과보다 좋았다.
그 이유로는,
- 최대길이의 단일문장을 사용함으로써 더 긴 문맥을 학습에 활용할 수 있고,
- NSP 사용 시, 순서가 섞인 두 문장에 의해 지나친 noise가 학습 시 추가되기 때문이다
512 길이의 single sequence 를 사용한 학습 (cf. BERT는 256씩 두개의 sequence 사용)
요약하자면 spanBERT는,
- geometric distribution을 사용하여 word-level의 span을 masking
- 사전학습에서 span-boundary objective를 auxiliary objective으로 사용
- single-sequence를 input 으로 사용
4. Experimental Setup
4.1 Tasks
- Task specific 방법 사용없이, linear classifier만을 추가
- Extractive Question Answering
- 다양한 domain 의 QA 데이터 평가로, 객관적인 일반화 성능 측정 시도
- SQuAD v1.1 (F1 94.6%)
- SQuAD v2.0 (F1 8.7%)
- NewsQA
- TriviaQA
- SearchQA
- HotpotQA
- Natural Questions
- X=[CLS]p1,...,pl[SEP]q1,...,ql[SEP]
- two linear classifier (start, end index)
- unanswerable → [CLS]
- MAX_LEN = 512, WINDOW = 128, epoch 4
- 다양한 domain 의 QA 데이터 평가로, 객관적인 일반화 성능 측정 시도
- Coreference Resolution
- span 이 어떤 entity인지 예측
- span에 대해 transformer encoding 사용
- 고정길이 span 사용
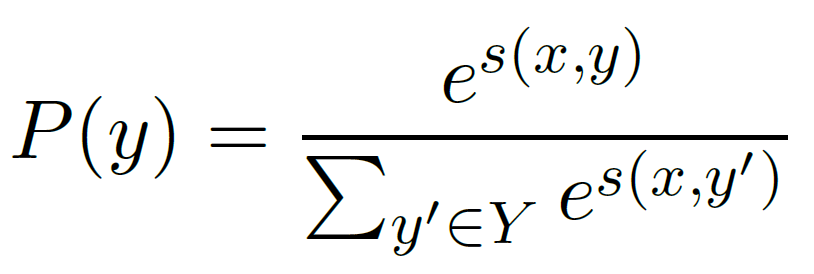
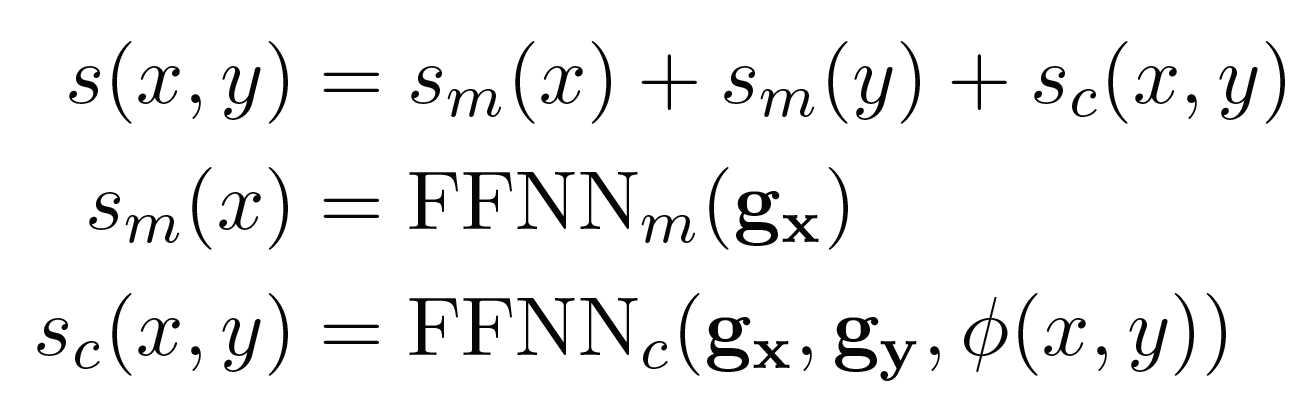
- gx : 2개의 transformer의 hs (span 양끝에 대한) concat
- gy : span token들에 attention score 적용한 representation
- ϕ(x,y) : 추가 feature (화자, 장르 정보)
- s(x,y) : span에 대한 최종 score 계산
- BS = 1 (document); 20 epoch
- Relation Extraction
- 단일문장, subject span, object span
- subject와 object의 관계 분류 (42개)
- subject, object를 NER로 대체하여 학습
- CLS 위치 : 관계 분류 output
- GLUE (9)
- 두 문장 분류 (2)
- CoLA (linguistic acceptability
- SST-2 (문장분류)
- 의미적 유사성 (3)
- MRPC : binary paraphrasing with news
- STS-B : news headlines
- QQP : binary paraphrasing with Quora question pairs
- 추론(NLI) (4)
- MNLI
- QNLI
- RTE
- WNLI
- MAX_LEN = 128
- 10 epochs (CoLA 4 epochs, 과적합 방지)
- 두 문장 분류 (2)
4.2 Implementation
- Google BERT, Our BERT : BERT-Large와 같은 양과 종류의 데이터 학습
- Our BERT
- 특정 학습 example 기준으로, 매 epoch마다 masking 수정
- cf. BERT는 10 epoch마다 masking을 수정
- 학습데이터에서 짧은 문장 제거
- 같은 document내에서 항상 최대길이인 512를 채워서 학습
- 특정 학습 example 기준으로, 매 epoch마다 masking 수정
- Hyperparameters
- linear warmup and decay : 10,000 step to 1e-4
- Dropout rate = 0.1
- GeLU
- 2.4M step → AdamW(epsilon = 1e-8)
- BS = 256 ; MAX_LEN = 512
- 200 dim for pos-emb in SBO
4.3 Baslines
- Google BERT
- Our BERT
- Our BERT-1seq : Our BERT에 NSP 제거 후 단일문장 학습
5. Results
5.1 Per-task Results
- Extractive Question Answering
- SQuAD v1.1, v2.0 : (+F1 2.0%, 2.8%)
- single sequence training (+1.1%)
- span masking, span boundary objective(+1.8%) : single sequence training 효과보다 더 크다
- Coreference Resolution
- F1 79.6% SOTA
- single sequence training : (+0.5%)
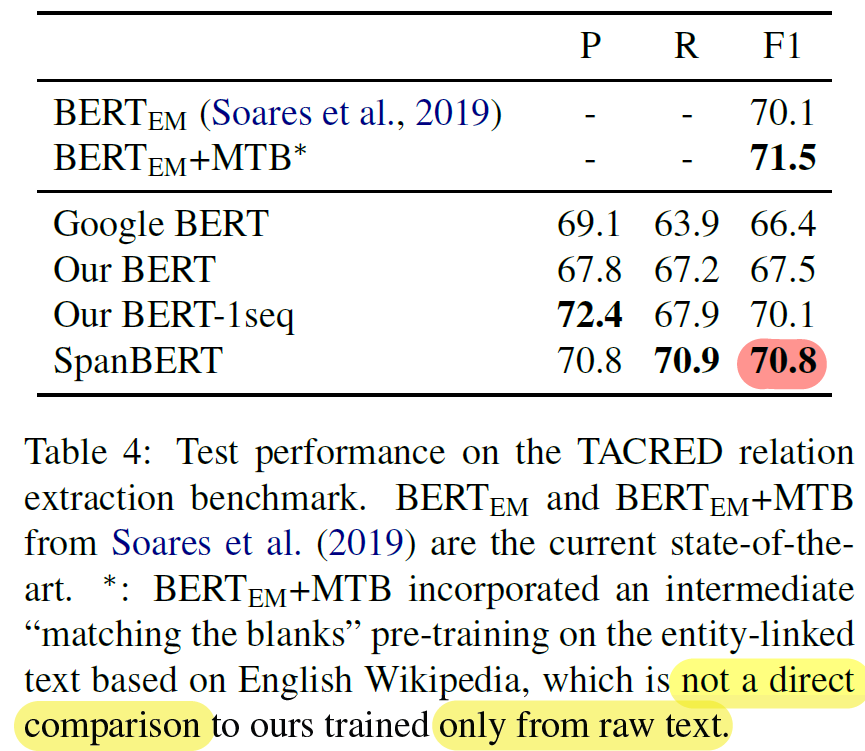
- Relation Extraction
- (+ F1 3.3%)
- single sequence training (+2.6%)
- span boundary objective (+0.7%)
- GLUE
- CoLA, MRPC, MNLI 향상
- SQuAD-based QNLI (+1.3%), RTE(+6.9%) : GLUE avg 향상에 높은 기여
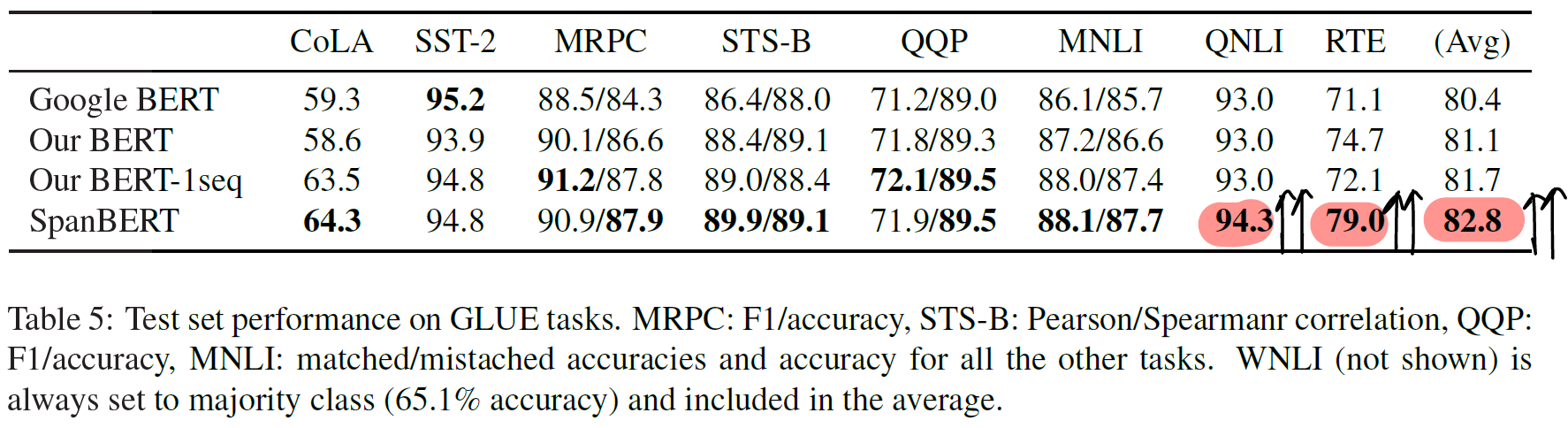
5.2 Overall Trends
- 17개 benchmark에서 spanBERT가 BERT를 대부분 능가한다
- spanBERT는 extractive QA에서 특히 큰 향상을 보였다
- single sequence 학습이 bi-sequence+NSP 학습보다 효과적이다
- 절반길이 사용으로 인해, 긴 문맥 학습을 저하한 것으로 예상
6. Ablation Studies
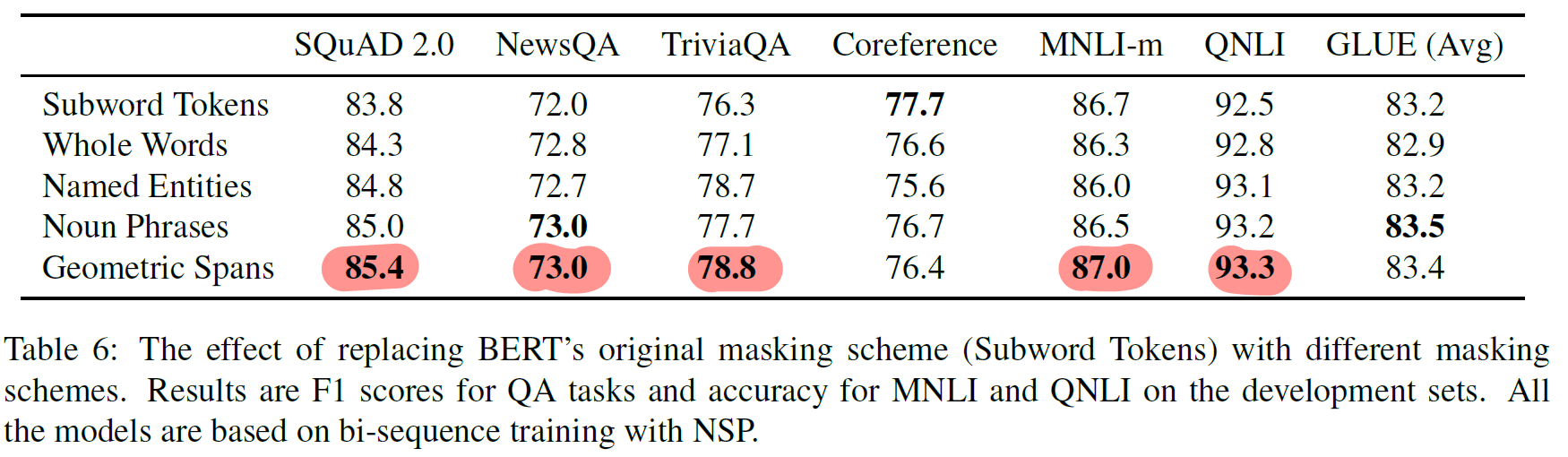
6.1 Masking Schemes
- Subword Tokens
- BERT의 masking 기법
- Whole Words
- word를 sampling 후 속하는 token 모두 masking (전체 token의 15%)
- Named Entities
- 15% masking
- spacy를 활용해 non numerical한 entity 추출 후 50% masking
- 50% 에 대해 whole word masking
- 15% masking
- Noun Phrases
- spacy 활용, noun phrase의 50% masking
- Geometric Spans
- spanBERT 의 masking 기법
Coreference Resolution 외에 spanBERT 기법 결과가 가장 좋음
6.2 Auxiliary Objectives : NSP vs SBO
- single sequence 학습 시 성능 향상
- SBO 추가 시, coreference resolution 에서 큰 향상 (F1 2.7%)
- SBO는 NSP와 달리 일관되게 성능 저하 영향X

7. Related Works
- Unlabeled text를 Large Model에 사전학습함으로써 문맥표현을 얻고 Fine-tuning 하는 방법들이 NLP 연구에서 주를 이루고 있다
- 여러 token을 제거하거나, phrase 나 named entity 기반 masking 관련 연구들이 존재
- ERNIE : 언어구조 지식 기반 사전학습 (개체명, 지식 그래프 사용)
- UNILM : 요약이나 QA 성능 향상을 위해 multi-task learning (unidirectional, bidirectional, seq2seq)을 사용
- XLM : 다국어 번역 향상
- Kermit : 기계번역, zero-shot QA 향상을 위해 제거된 token을 복원하는 task
- RoBERTa : hyperparameter, 데이터 사이즈의 영향에 대한 성능 기여 정도 실험
- XLNet : 데이터 증가, Autoregressive language modeling, mask span 사용(partial prediction)
- pair2vec : word-pair representation을 학습해서 downstream task에서 활용, SBO를 사용한 spanBERT는 representation을 fine-tuning 함으로써 downstream task에 더 적합한 가중치로 조정
8. Conclusion
- 사전학습 시, 연속적인 토큰들(span)에 대해 masking 하고,
- mask 토큰을 예측하는데 span boundary 의 representation 을 활용하도록 학습한 spanBERT는,
- BERT를 이기고, 여러 downstream task에서 성능향상을 보여주었으며, 특히 span-level task에서 정도가 유의미하였다
스터디원들과의 QnA 및 Discussion
Q1. Representation 이란?
A1. 모델이 학습한 weight들을 통해 input text 를 표현하는 output embedding vector를 가리키는 뜻으로 쓰인다. 좀 더 깊이 있게 현재 NLP Trend 관점에서 보자면, dense representation 을 뜻한다고도 볼 수 있다. 해당 용어가 사용된 것은, 정해진 dimension 의 vector 가 단어, 구, 또는 문장을 표현하도록 주변 단어를 통해 학습되기 때문이다. 이러한 방식은 word2vec 부터, Transformer 기반 language model을 Pre-training 하는 현재의 방식까지 이어져오고 있다.
Q2. span 의 정의는?
A2. 논문과 NLP Task 에서 사용되는 span은 두 개 이상의 연속된 token sequence를 뜻하는 것으로 보인다. 논문에서는 주로 기본 단위가 tokenizer 에 의해 분절되는 individual token 이기에 이와 상반되는 개념이라고 볼 수 있다. 두 개 이상의 연속된 token 에 해당하는 span은 실제 자연어에서의 일정한 단위라고 말하기는 어렵다. 왜냐하면, span이 구성할 수 있는 자연어에서의 단위가 하나의 단어부터, 문장에 이르기까지 다양할 수 있기 때문이다.
Q3. fine-tuning approach 에서의 discrepancy 란 무엇인가?
A3. Pre-training 시, 모델은 [MASK] token 이 포함된 input text를 사용하여 학습한다. Pre-train을 마치면, [MASK] token 의 embedding vector 에 문맥을 따라 학습한 상당한 정보가 포함될 것으로 예상해볼 수 있다. 그러나 fine-tuning 에서의 input text에서는 [MASK] token 이 포함되어 있지 않다. 따라서 [MASK] 토큰에 포함된 context 정보를 사용하지 못하고, 그대로 버리게 되는 것이다. 이러한 오랜 시간 사전학습을 통해 얻게된 정보를 사용하지 못하는 것은 자원적으로도, 성능에도 비효율(loss)일 수 밖에 없다.
Q4. 논문에서 Our bert는 어떤 BERT를 지칭하는 것인가?
A4. 4.2 Implementation 의 두 번째 문단에서, 저자가 일부 improvement 방법을 적용하여 기존과 다른 BERT를 구현하여, spanBERT와 함께 비교할 것임을 기술하고 있다. 수정된 저자의 BERT는, (a) 매 epoch마다 input의 masking 패턴을 수정하는 방식을 사용하고, (b) 랜덤샘플링을 통한 short-sequence input 생성 방법을 제외하여, 모든 input 을 512 길이로 구성하고, 일부 하이퍼파라미터를 수정하여 학습한 모델이다.
Q5. Span Boundary Objective (SBO) 의 효과는?
A5. 모델은 SBO를 통해 양쪽 boundary token 정보만으로 span 의 각 token 들을 예측하도록 학습된다. 해당 과정에서 boundary token 들의 representation에 span 의 문맥정보를 최대한 포함하는 방향으로 update 된다고 볼 수 있다.
Q6. Relation Extraction task 란 ? (TACRED Dataset)
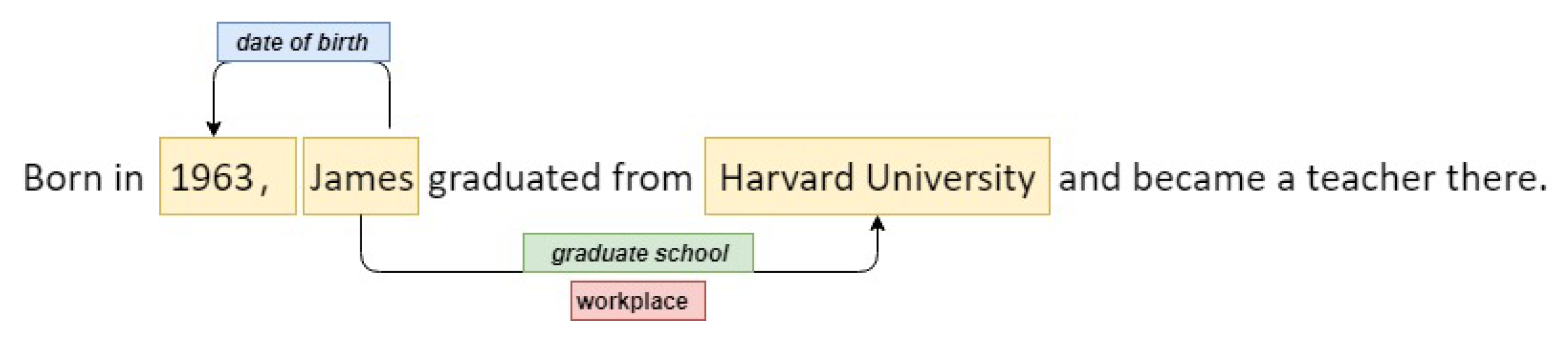
A6. 주어진 문장 내에서 subject와 object 간의 문맥적 관계를 예측하는 task 이다.
위의 이미지는 Relation Extraction task 학습을 위한 데이터의 예시이다. 위 문장에서는 3개의 example을 학습할 수 있다.
- James (subject) 와 1963 (object) 의 관계는 date of birth
- James (subject) 와 Harvard University (object) 의 관계는 graduate school
- James (subject) 와 Harvard University (object) 의 관계는 workplace
학습을 위한 example pair 을 rough하게 구성해보자면 다음과 같다. 물론 아래와 다른 순서로 input 구성을 할 수도 있다.
Input1 : Born in 1963, James graduated from Harvard University and became a teacher there ; James ; 1963 Target1 : date of birth
Input2 : Born in 1963, James graduated from Harvard University and became a teacher there ; James ; Harvard University
Target2 : graduate school
Input3 : Born in 1963, James graduated from Harvard University and became a teacher there ; James ; Harvard University
Target3 : workplace
<Reference>
Joshi, M., Chen, D., Liu, Y., Weld, D. S., Zettlemoyer, L., & Levy, O. (2020). Spanbert: Improving pre-training by representing and predicting spans. Transactions of the Association for Computational Linguistics, 8, 64-77.





댓글 영역