고정 헤더 영역
상세 컨텐츠
본문 제목
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations 논문리뷰
본문
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations 논문리뷰
Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다
Abstract

- 모델 크기 증가 한계
- GPU/TPU 메모리 제한
- 긴 학습시간 소요
- Parameter Reduction Technique
- 낮은 메모리 사용
- 학습 속도 증가
- SOP : 문장 간 coherence 정보 학습
- BERT-LARGE보다 적은 파라미터로 GLUE, SQuAD, RACE 에서 SOTA
1. Introduction
- Language Representation 학습을 위해 Pre-training 사용
- 특히나 기계독해 부분에서의 성능 향상이 괄목할만하다(44.1% → 89.4%)
- Large Model이 특히 중요
- Pre-training → Knowledge Distillation
- 모델 크기 증가의 한계
- Memory limitation 해결
- Model Parallelization (모델 병렬화)
- Memory management 기법
- communication overhead
- 파라미터 수에 비례
- 미해결
- Memory limitation 해결
ALBERT
- Parameter Reduction Techniques
- factorized embedding parameterization
- 큰 Embedding matrix 를 두 개의 작은 matrix로 분해한다
- hidden size를 증가하는 것과 관계 없이, embedding dimension 을 설정할 수 있어, embedding layer의 파라미터 수가 지나치게 증가하는 것을 막을 수 있다
- Cross layer parameter sharing
- 깊게 layer를 쌓음에 따라 파라미터 수가 증가하는 것을 막을 수 있다
- 파라미터들에 Regularization 효과를 제공함으로써 일반화 성능을 높인다
- BERT-LARGE보다 18배 적은 수의 파라미터를 가지며, 1.7x 빠르게 학습하는 장점을 가진다
- factorized embedding parameterization
- sentence-order prediction (SOP)
- inter-sentence coherence : 문장 간 일관성을 잘 학습하도록 한다, NSP를 보완한다
- SOTA : GLUE 89.4%, SQuAD 2.0 92.2%, RACE : 89.4%
ALBERT 의 기법으로 대용량 모델을 학습했고, BERT-LARGE 보다 적은 수의 파라미터를 가지지만 더 나은 성능을 보여주었다.
2. Related Work
2.1 Scaling Up Representation Learning For Natural Language
- 기존 Trend : Pre-training Word Embeddings (standard, contextualized)
- 현재 Trend : pre-training + task-specific fine-tuning
- RoBERTa : larger model → higher performance, 그러나 GPU, TPU 메모리 제한 문제
- GPU, TPU 메모리 제한 문제 해결
- gradient checkpoint
- activation reconstruction
- model parallelization
ALBERT는 메모리제한 문제 해결 + 학습 속도 향상
2.2 Cross-layer Parameter Sharing
- 선행연구에서는 Pre-train 하지 않는 일반적 Transformer 구조에서 사용 : language modeling + subject-verb agreement에서 우세
- DQE(Deep Equilibrium Model) : input embedding과 다른 layer의 output embedding 유사 → ALBERT 실험에서는 상이 (유사도가 수렴이 아닌, 진동)
- parameter sharing Transformer + Standard Transformer : 성능 우세
2.3 Sentence Ordering Objectives
- Sentence Ordering Prediction (SOP) : 두 개 연속된 text segment에 대해 순접인지, 역순인지 예측하는 objective
- Objective to learn discourse coherence (sentence embedding)
- 주변 문장의 단어 예측 : (Kiros et al., 2015; Hill et al., 2016)
- 미래 문장 예측 : (Gan et al., 2017)
- 문장의 given marker 예측 : (Jernite et al., 2017; Nie et al., 2019)
- 문장 순서 예측 (SOP와 유사) : Wang et al. (2019)
- ALBERT는 선행연구와 달리 sentence가 아닌 segment 단위를 다룬다.
- BERT의 NSP에서 negative sample은 서로 다른 document의 segment 들로 구성했다
- Wang et al. (2019) 에서 NSP + SOP, ALBERT는 NSP vs SOP 연구를 수행한다
3. The Elements of ALBERT
3.1 Model Architecture Choices
- Transformer Encoder 기반 (= BERT) + GeLU
- FFPN = 4H; A = H/64
Factorized embedding parameterization
모델 내에서 Embedding vector 을 context 측면에서 두 가지로 분류할 수 있다.
- Wordpiece Embedding : context-independent representation
- Hidden-layer Embedding : context-dependent representation, 모델의 성능에 중요한 영향을 미치며, Hidden size를 늘릴 때, 파라미터 수가 증가하여 학습효과를 향상할 수 있다
그러나, $E = H$ 이므로, 모델의 Hidden size를 증가시키고자 할 때, embedding layer의 파라미터가 지나치게 크게 발생하는 문제 존재한다. 즉, Hidden size의 조정이 Embedding vector의 dimension과 분리되지 못하고 있다
이를 위해, Embedding matrix를 두 개의 작은 matrix로 분해한다
hidden size를 증가하는 것과 관계 없이, embedding dimension 을 설정할 수 있어, embedding layer의 파라미터 수의 지나친 증가가 필수적이지 않게된다 (Parameter Reduction)
이를 수식으로 나타내면,
- $O(V \times E ) \to O(V \times E + E \times H )$
- 특히, $H >> E$ 일 때 parameter 감소 효과 더 크게 나타난다
ex.
- O(V x D) : (30522 x 768) = 23440896
- O(V x E + E x D) : (30522 x 128) + (128 x 768) = 4005120 (5.85x)
Cross-layer parameter sharing
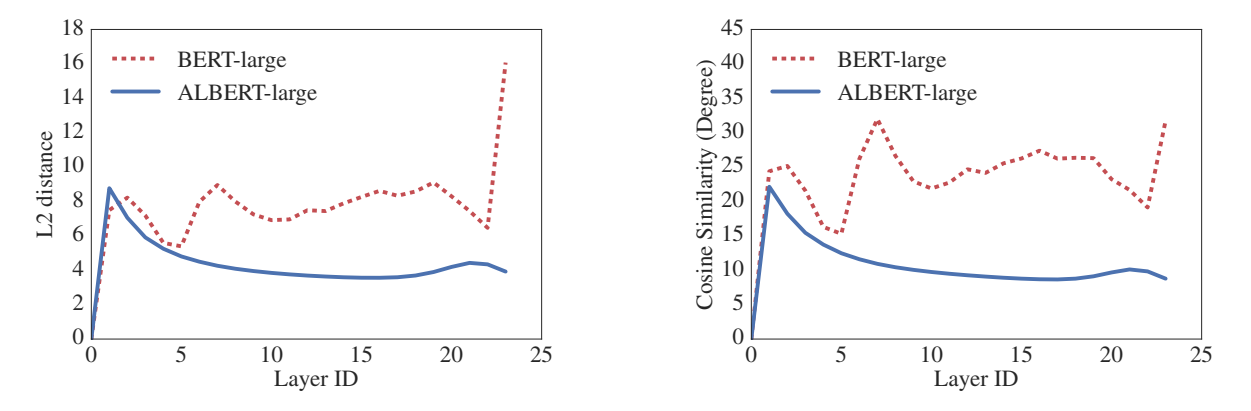
- BERT와 비교한 ALBERT의 Output Embedding은 input embedding 과의 차이를 나타내는 그래프에서 더 smooth 했다
- input, output embedding vector가 벡터공간에서 서로 가까이 위치하고, Parameter 에게 stabilizing 하는 효과에 영향을 받았다고 볼 수 있다.
- 즉, parameter sharing 을 통해, input, output embedding vector 간 의미가 유사해지므로 (cosine distance), 일종의 Regularization 효과가 적용되었다고도 볼 수 있다 (Generalization)
- 다만, DQE와 달리 layer가 깊어져도 거리가 완전히 0에 수렴하지는 않았다. 이는, ALBERT와 DQE의 해공간이 다름을 의미한다
Inter-sentence coherence loss
- BERT : MLM + NSP, 그러나 이후 연구에서 NSP 효과에 대해 의문이 제기되었고, 결국 제거되었다
- NSP는 서로 다른 document 에 속한 segment 조합 여부를 예측하므로, Topic Prediction 을 답습한다는 측면에서 MLM과 Overlap이 높은 loss 이다. 따라서 문장 순서 예측에 효과적인 loss라고 해석하기 어렵다
- SOP는 topic prediction을 제거하여 inter-sentence coherence에 대해 더 큰 학습 효과를 제공한다
- Negative sample 을 생성할 때 BERT와 달리 동일한 document 의 segment를 사용하기 때문이다. 다만 순서를 역순으로 구성하여 (swap) 바뀐 순서를 올바르게 인식하도록 모델이 학습하게 된다
- SOP에서의 이러한 segment 구성은 모델로 하여금 더 정밀한 discourse-level coherence 를 학습하도록 돕는다
3.2 Model Setup

- BERT-large : 334M Params
- ALBERT-large : 18M (BERT-large 보다 18x 적은 숫자)
- ALBERT-xlarge (H=2048) : 60M
- ALBERT-xxlarge(H=4096, 12 layer) : 233M
4. Experimental Results
4.1 Experimental Setup
- Bookcorpus + English Wikipedia (16GB) : BERT와 동일
- Max_seq_len = 512 (Random 10% 는 512 미만으로 생성)
- V = 30000 (sentencepiece in XLNet)
- BS = 4096, LAMB(LR = 0.00176), 125000 steps, 64 ~ 512 TPUs
- n-gram masking (random length sampling, max = 3, word 단위)
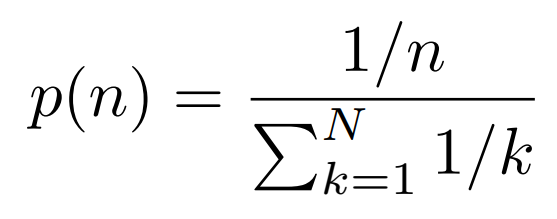
4.2 Evaluation Benchmarks
4.2.1 Intrinsic Evaluation
- MLM, SOP, NSP task 자체에 대한 성능 측정 시도 : benchmark 데이터의 dev-set 활용
4.2.2 Downstream Evaluation
- GLUE, SQuAD, RACE
- earlystopping on dev set
- GLUE는 median 5 runs; large variance on dev-set
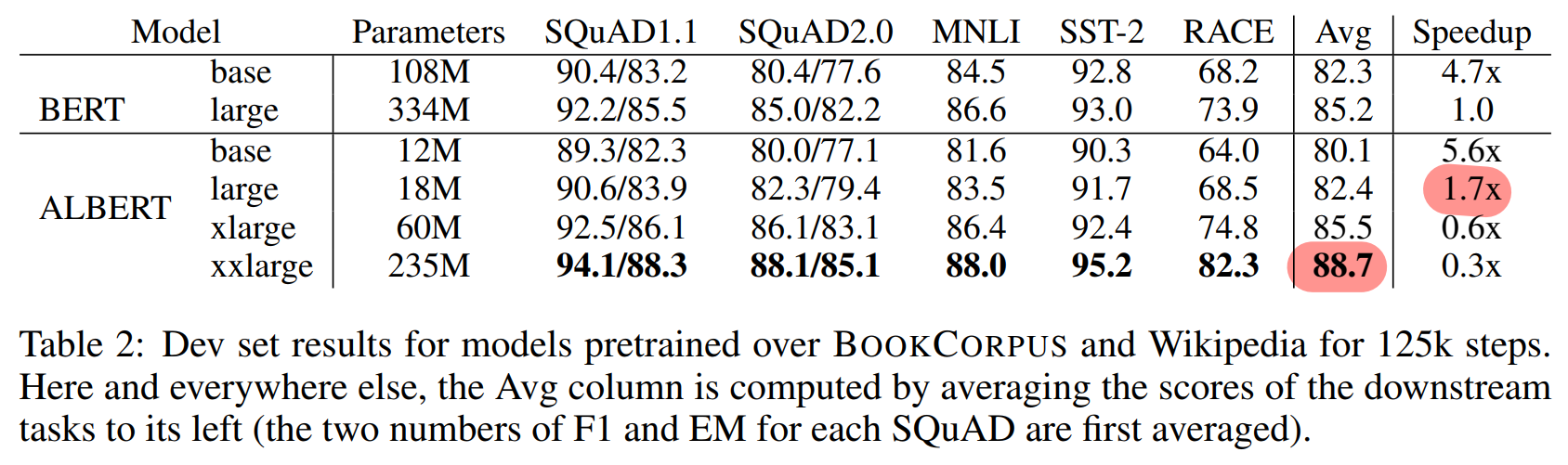
4.3 Overall Comparison Between BERT and ALBERT
- (성능) ALBERT-xxlarge : BERT-large 파라미터 수의 70% 로 SOTA
- SQuAD v1.1 (+1.9%)
- SQuAD v2.0 (+3.1%)
- MNLI (+1.4%), SST-2 (+2.2%)
- RACE (+8.4%)
- (학습속도) : ALBERT-large는 BERT-Large의 1.7배 빠른 속도
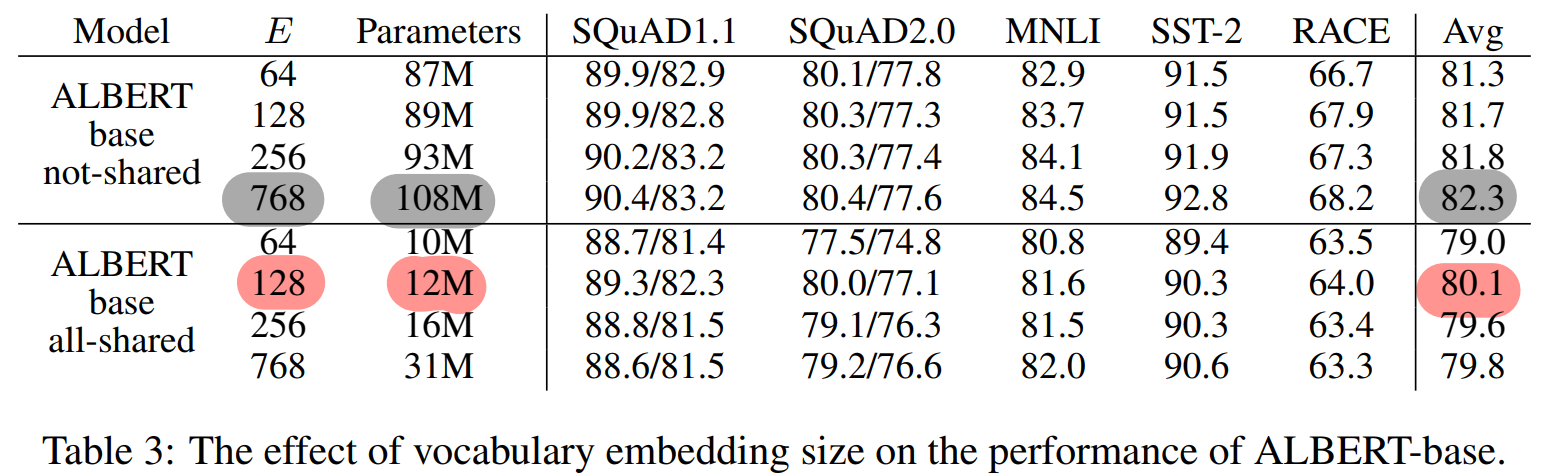
4.4 Factorized Embedding Parameterization
- non-shared : 성능증가를 위해서 Embedding size 증가 (미미한 효과)
- all-shared(ALBERT) : Embedding size 128 이 가장 우세
- parameter-share과 embedding decompose 결합 시 작은 E를 사용하여, 효율성 증대 발생
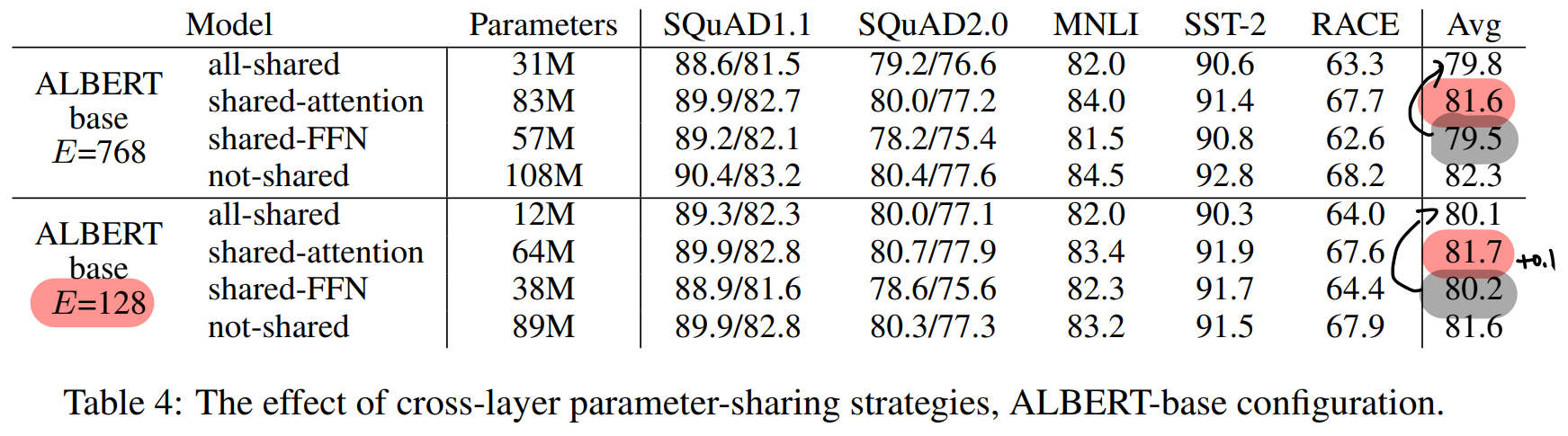
4.5 Cross-layer Parameter Sharing
- FFN share 시 큰 성능 drop 발생
- attention-share에서는 성능 drop이 작거나(E=768) 발생하지 않는다(E=128)
- Group sharing 전략도 가능 → M개의 layer로 이루어진 Group 단위로 sharing → M 을 줄일 때마다 parameter 수 증가, 사용X
4.6 Sentence Order Prediction (SOP)
- Inter-sentence loss 간에 성능 실험
- None (ex. XLNet, RoBERTa)
- NSP (ex. BERT)
- SOP (ex. ALBERT)
- SOP 사용 우세
- around +1% for SQuAD1.1
- +2% for SQuAD2.0
- +1.7% for RACE)
- around +1% Avg score

4.7 Train For The Same Amount Of Time?
- 동일한 시간 학습 시, ALBERT-xxlarge 우세 (+1.5% Avg, +5.2% RACE)

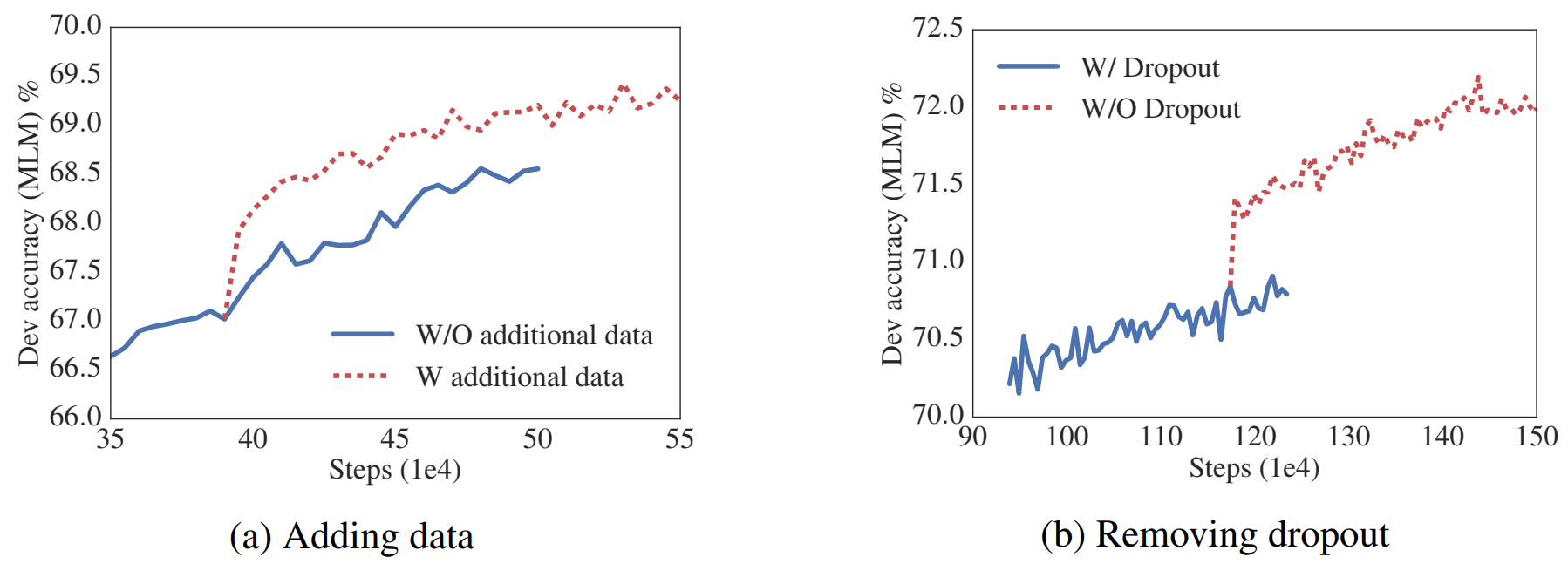
4.8 Additional Training Data and Dropout Effect
추가데이터 사용 (XLNet, RoBERTa 데이터)
- dev-set에서 전반적인 성능 향상
- SQuAD 성능 감소 : 관련 데이터인 Wiki 이외 다른 데이터 추가에서 기인

Dropout 제거
- 사전학습에서 Dropout 제거 시, MLM 정확도 향상
- ALBERT : Transformer 기반 구조에서 dropout 사용 시 성능 drop 발생한 case

즉, 추가데이터 사용하고, Dropout 제거하는 것이 Pre-train에 도움된다
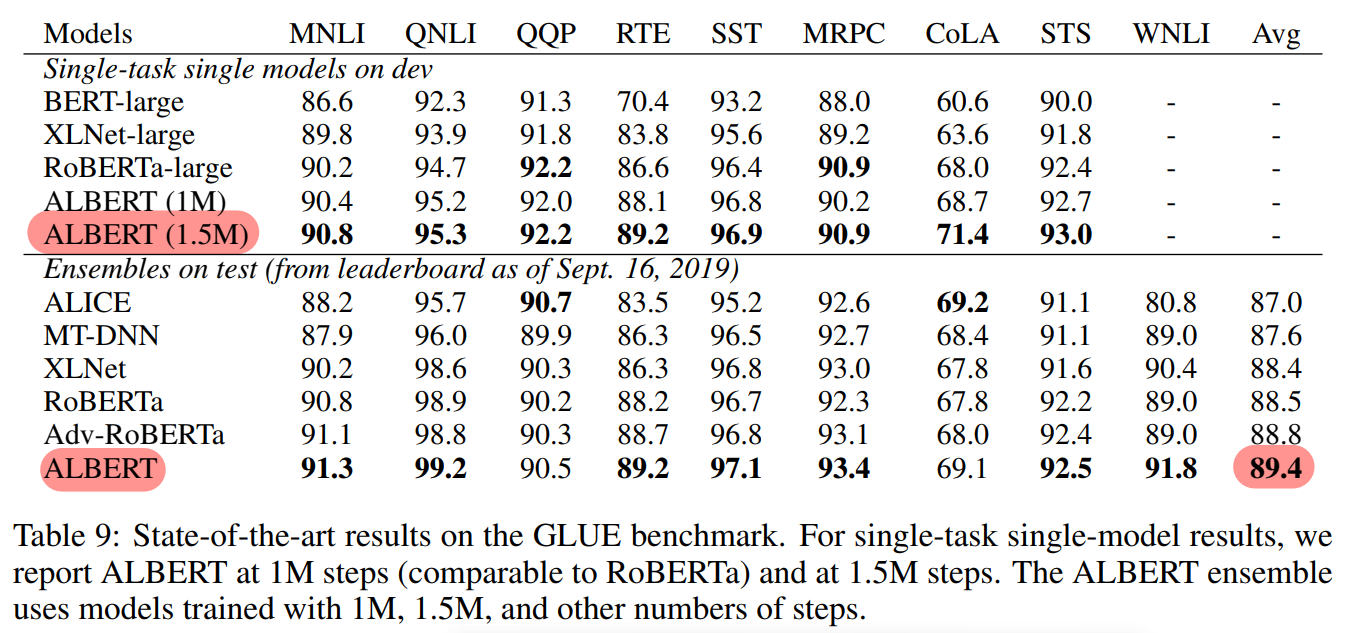
4.9 Current SOTA on NLU Tasks
- ALBERT-xxlarge (1M, 1.5M) : MLM + SOP + no dropout
- GLUE, SQuAD, RACE에서 single 모델 및 ensemble 모델들보다 높은 성능
- ALBERT Ensemble : 상이한 n_step, n_layer 의 6~17개 checkpoint 앙상블 실험 (최적 개수는 제시X)

5. Discussion
- 향후 ALBERT 학습 속도 향상 연구
- sparse attention (Child et al., 2019)
- block attention (Shen et al., 2018)
- Representation 향상 필요
- hard example mining (Mikolov et al., 2013)
- more efficient language modeling training (Yang et al., 2019)
- SOP 이외에 다른 objective 또한 기대
DistilBERT Code Implementation
SOP 를 위한 Input Settting
연속된 segment-pair (token_a, token_b) 에 대해 일정확률로 순서를 swap 해준다. 이 때, segment-pair는 최대길이를 넘지 않는 않게 구성한다.
# input 구성
is_next = rand() < 0.5 # whether token_b is next to token_a or not
# segment 단위 : len_tokens 만큼의 token (완전한 문장 단위X)
tokens_a = self.read_tokens(self.f_pos, len_tokens, True)
seek_random_offset(self.f_neg)
#f_next = self.f_pos if is_next else self.f_neg
f_next = self.f_pos # `f_next` should be next point
tokens_b = self.read_tokens(f_next, len_tokens, False)
if tokens_a is None or tokens_b is None: # end of file
self.f_pos.seek(0, 0) # reset file pointer
return
# sentence-order prediction (SOP)
instance = (is_next, tokens_a, tokens_b) if is_next \
else (is_next, tokens_b, tokens_a)
Factorizing Embedding Matrix
아래는 BERT 구현 코드이다. Embedding layer 이 Vocab_num X Dimension 으로 차원의 수가 hidden_num과 분리되지 않으며, 많은 수의 parameter로 구성될 수 밖에 없는 구조이다. (V x D = 30522 x 768 = 23440896)
# BERT Config
class Config(NamedTuple):
"Configuration for BERT"
vocab_size: int = 30522 # Size of Vocabulary
dim: int = 768 # Dimension of Hidden Layer in Transformer Encoder
n_layers: int = 12 # Numher of Hidden Layers
n_heads: int = 12 # Numher of Heads in Multi-Headed Attention Layers
dim_ff: int = 768*4 # Dimension of Intermediate Layers in Positionwise Feedforward Net
#activ_fn: str = "gelu" # Non-linear Activation Function Type in Hidden Layers
p_drop_hidden: float = 0.1 # Probability of Dropout of various Hidden Layers
p_drop_attn: float = 0.1 # Probability of Dropout of Attention Layers
max_len: int = 512 # Maximum Length for Positional Embeddings
n_segments: int = 2 # Number of Sentence Segments
# BERT : Embedding Matrix (V x D)
class Embeddings(nn.Module):
"The embedding module from word, position and token_type embeddings."
def __init__(self, cfg):
super().__init__()
# (V x D) : 30522 x 768 = 23440896
self.tok_embed = nn.Embedding(cfg.vocab_size, cfg.dim) # token embedding
self.pos_embed = nn.Embedding(cfg.max_len, cfg.dim) # position embedding
self.seg_embed = nn.Embedding(cfg.n_segments, cfg.dim) # segment(token type) embedding
self.norm = LayerNorm(cfg)
self.drop = nn.Dropout(cfg.p_drop_hidden)
def forward(self, x, seg):
seq_len = x.size(1)
pos = torch.arange(seq_len, dtype=torch.long, device=x.device)
pos = pos.unsqueeze(0).expand_as(x) # (S,) -> (B, S)
e = self.tok_embed(x) + self.pos_embed(pos) + self.seg_embed(seg)
return self.drop(self.norm(e))
아래는 ALBERT의 구현 코드이다. Embedding layer에서, 기존의 VxD의 큰 parameter matrix를 두 개의 작은 matrix로 분해했다. (V x E, E x D) 이를 통해, embedding layer에서의 dimension 수를 hidden_num과 다르게 지정할 수 있는 구조가 되어, embedding layer에서의 parameter reduction 효과를 얻을 수 있게 되었다. (23440896 -> 4005120, 약 5.8x 감소)
# ALBERT Config
class Config(NamedTuple):
"Configuration for ALBERT"
vocab_size: int = 30522 # Size of Vocabulary
hidden: int = 768 # Dimension of Hidden Layer in Transformer Encoder
hidden_ff: int = 768*4 # Dimension of Intermediate Layers in Positionwise Feedforward Net
embedding: int = 128 # Factorized embedding parameterization
n_layers: int = 12 # Numher of Hidden Layers
n_heads: int = 768//64 # Numher of Heads in Multi-Headed Attention Layers
#activ_fn: str = "gelu" # Non-linear Activation Function Type in Hidden Layers
max_len: int = 512 # Maximum Length for Positional Embeddings
n_segments: int = 2 # Number of Sentence Segments
# ALBERT : 2 Embedding Matrix (V x E + E x D)
class Embeddings(nn.Module):
"The embedding module from word, position and token_type embeddings."
def __init__(self, cfg):
super().__init__()
# Original BERT Embedding
# self.tok_embed = nn.Embedding(cfg.vocab_size, cfg.hidden) # token embedding
# factorized embedding
# (V x E + E x D) : (128 x 30522) + (128 x 768) = 4005120
self.tok_embed1 = nn.Embedding(cfg.vocab_size, cfg.embedding)
self.tok_embed2 = nn.Linear(cfg.embedding, cfg.hidden)
self.pos_embed = nn.Embedding(cfg.max_len, cfg.hidden) # position embedding
self.seg_embed = nn.Embedding(cfg.n_segments, cfg.hidden) # segment(token type) embedding
self.norm = LayerNorm(cfg)
# self.drop = nn.Dropout(cfg.p_drop_hidden)
def forward(self, x, seg):
seq_len = x.size(1)
pos = torch.arange(seq_len, dtype=torch.long, device=x.device)
pos = pos.unsqueeze(0).expand_as(x) # (S,) -> (B, S)
# factorized embedding
e = self.tok_embed1(x)
e = self.tok_embed2(e)
e = e + self.pos_embed(pos) + self.seg_embed(seg)
#return self.drop(self.norm(e))
return self.norm(e)
Parameter Sharing
모든 layer에 대해 동일한 parameter 들에 propagation을 수행하였다. 아래의 BERT에서는 layer(block)을 이루는 파라미터들을 다르게 사용하였고, 이로 인해 전체 파라미터 수가 상대적으로 많았다. 반면 ALBERT의 코드를 보면, 깊은 layer에서도, 동일한 파라미터에 대해 연산이 이루어져, 여러 layer 사용에도 propagation 수가 늘어날 뿐, 결국 한 개 layer(block) 의 파라미터 수만큼만 사용됨을 알 수 있다.
# BERT : individual block (different parameter)
class Transformer(nn.Module):
""" Transformer with Self-Attentive Blocks"""
def __init__(self, cfg):
super().__init__()
self.embed = Embeddings(cfg)
self.blocks = nn.ModuleList([Block(cfg) for _ in range(cfg.n_layers)])
def forward(self, x, seg, mask):
h = self.embed(x, seg)
for block in self.blocks:
h = block(h, mask)
return h
class Block(nn.Module):
""" Transformer Block """
def __init__(self, cfg):
super().__init__()
self.attn = MultiHeadedSelfAttention(cfg)
self.proj = nn.Linear(cfg.dim, cfg.dim)
self.norm1 = LayerNorm(cfg)
self.pwff = PositionWiseFeedForward(cfg)
self.norm2 = LayerNorm(cfg)
self.drop = nn.Dropout(cfg.p_drop_hidden)
def forward(self, x, mask):
h = self.attn(x, mask)
h = self.norm1(x + self.drop(self.proj(h)))
h = self.norm2(h + self.drop(self.pwff(h)))
return h
# ALBERT : Parameter sharing
class Transformer(nn.Module):
""" Transformer with Self-Attentive Blocks"""
def __init__(self, cfg):
super().__init__()
self.embed = Embeddings(cfg)
# Original BERT not used parameter-sharing strategies
# self.blocks = nn.ModuleList([Block(cfg) for _ in range(cfg.n_layers)])
# To used parameter-sharing strategies
self.n_layers = cfg.n_layers
self.attn = MultiHeadedSelfAttention(cfg)
self.proj = nn.Linear(cfg.hidden, cfg.hidden)
self.norm1 = LayerNorm(cfg)
self.pwff = PositionWiseFeedForward(cfg)
self.norm2 = LayerNorm(cfg)
# self.drop = nn.Dropout(cfg.p_drop_hidden)
def forward(self, x, seg, mask):
h = self.embed(x, seg)
for _ in range(self.n_layers):
# h = block(h, mask)
h = self.attn(h, mask)
h = self.norm1(h + self.proj(h))
h = self.norm2(h + self.pwff(h))
return h스터디원들과의 QnA 및 Discussion
Q. Intrinsic task (SOP, NSP) 의 측정은 어떻게 이루어졌을까?
A. SQuAD, RACE 의 dev-set에 대해 각 pre-train objective (SOP, NSP) 에 맞게 Inference 를 진행할 수 있는 형태로 재구성했을 것으로 보인다. input으로 활용하기 위해 각 objective에 맞게 positive, negative sample들을 생성하고, 원본 text를 target으로 하여, 성능을 측정할 수 있었을 것이다.
Q. Paper의 초기버전과 최종버전을 비교했을 때, Result 부분에서, BERT-xlarge 를 추가한 것을 볼 수 있다. 이것은 어떤 의미일까.
A. 초기버전에서는 ALBERT-xxlarge 와의 성능은 BERT-large와 비교하는데, 학습 속도는 BERT-base와 비교하여, 비교에서의 일관성이 낮다고 느껴졌었다. 그런데 성능 및 학습 시간 모두 BERT-xlarge 와 비교하여 더 좋은 결과를 가진다는 것을 보여주게 되어, 비교의 객관성을 보완하고, 모델의 우수성을 더 효과적으로 어필했다고 느껴졌다
BERT의 저자들 중 NSP 사용에 기여한 사람은 누굴까.. 그는 대체 어떤 죄를 지었기에 이토록 많은 논문을 통해 고통받아야 하는가. (혹시 다수의 Citation을 위한 큰 그림은 아니겠지.....? 만약 그렇다면 역시 "Google Brain"....
<Reference>
Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942





댓글 영역