고정 헤더 영역
상세 컨텐츠
본문 제목
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
본문

BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 리뷰
Google Machine Learning Bootcamp 2022 에서 "NLP 논문 리뷰 스터디" 에 참여하며 정리한 자료입니다
Abstract

BART : pretrained seq2seq (denoising-autoencoder)
- 임의의 noising function 을 통해 input text corruption
- 원본 text를 복구하도록 학습
여러가지 noising 기법 중 결과가 좋았던 2가지 방식 소개
- 문장 순서를 random하게 shuffling
- 일부 연속된 token의 span을 단일 [mask] 토큰으로 대체
BART의 우수한 성능 : discriminative, generative task
- GLUE와 SQuAD에서 더 효율적인 연산으로 비슷한 성능
- Generation task (abstractive dialogue, question answering, summarization)에서 SOTA 달성 (최대 6 ROUGE)
- 특히 Machine Translation에서는 Target Language에 대한 사전학습만으로, Back Translation 기법 사용 결과보다 나은 성능 (1.1 BLEU)
1. Introduction
기존 MLM 방식의 Pre-trained 모델의 한계
- NLP에서의 Self-supervised 방식의 약진 : Masked Language Modeling
- 랜덤하게 일정 단어들을 masking 처리 후, 이를 복원 가능한 방향으로 학습
- MLM 기법 변형 시도
- spanBERT : 개별 토큰 마스킹 → 연속된 토큰 마스킹 (span)
- XLNet : permutation 과 language modeling 결합 (bidirectional)
- UniLM
- 특정 MLM 기법에 적합하도록 학습되기에, applicability 저하 우려
BART 소개
- 일반화 성능이 더 뛰어난 noising function 사용
- 원본 문장들의 순서 shuffling
- 임의의 길이의 토큰들을 하나의 [MASK]로 대체
- 전반적인 문장 길이를 추론하고, 더 긴 범위의 text 를 학습에 사용하도록 함
- generation에 적합한 seq2seq 모델 구조 사용
- GPT, BERT의 일반화된 모델
- Comprehension 및 Generation에서 모두 뛰어난 성능
- Comprehension : GLUE, SQuAD
- Generation : Abstractive dialogue, QA, summarization
- Machine Translation 의 새로운 fine-tuning 기법 제안
- Target language 에 대해 pre-trained 된 모델에 Transformer 일부 layer를 추가로 활용하는 것만으로, 두 언어에 대한 augmentation 에 해당하는 back-translation 기법을 사용한 것보다 좋은 성능을 보여주었다.
2. Model
- Denoising Autoencoder : masking 된 문서에 대해 원본 텍스트를 복구하도록 학습
- seq2seq = bidirectional encoder + left-to-right autoregressive decoder
2.1 Architecture
- Transformer 구조 + GeLU
- init from N(0,0.02)
- base : 6 layers / large : 12 layers
- BERT와의 차이점
- decoder 의 모든 layer에서 encoder의 마지막 layer의 hidden states 와 cross-attention 수행
- decoder의 layer 내에서 prediction 직전 Feed-forward network 제거
- BERT보다 10% 많은 params
2.2 Pre-training BART
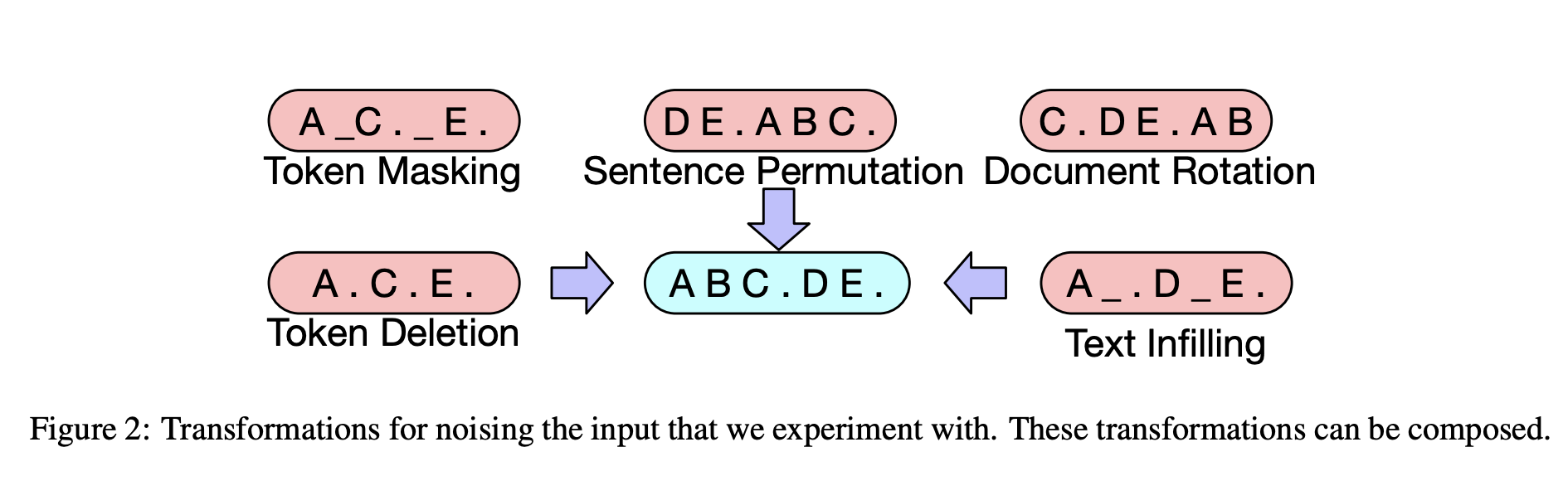
- Token Masking : 임의의 토큰을 [MASK] 로 대체 후 해당 토큰의 원본 토큰 예측
- Token Deletion : 임의의 토큰 삭제 후, (토큰 자체가 아닌) 삭제된 위치를 예측
- Text Infilling
- span length sampling : Poisson (λ= 3)
- 해당 span은 단일 [MASK]로 대체 (0-length는 단순히 [MASK] 추가)
- 삭제된 토큰 수를 유추하도록 학습
- Sentence Permutation : 문장들을 random 순서로 shuffle (어떻게 맞추지???)
- Document Rotation : 특정 토큰 기준으로 문장 시작을 재구성 (순환구조)
3. Fine-tuning BART
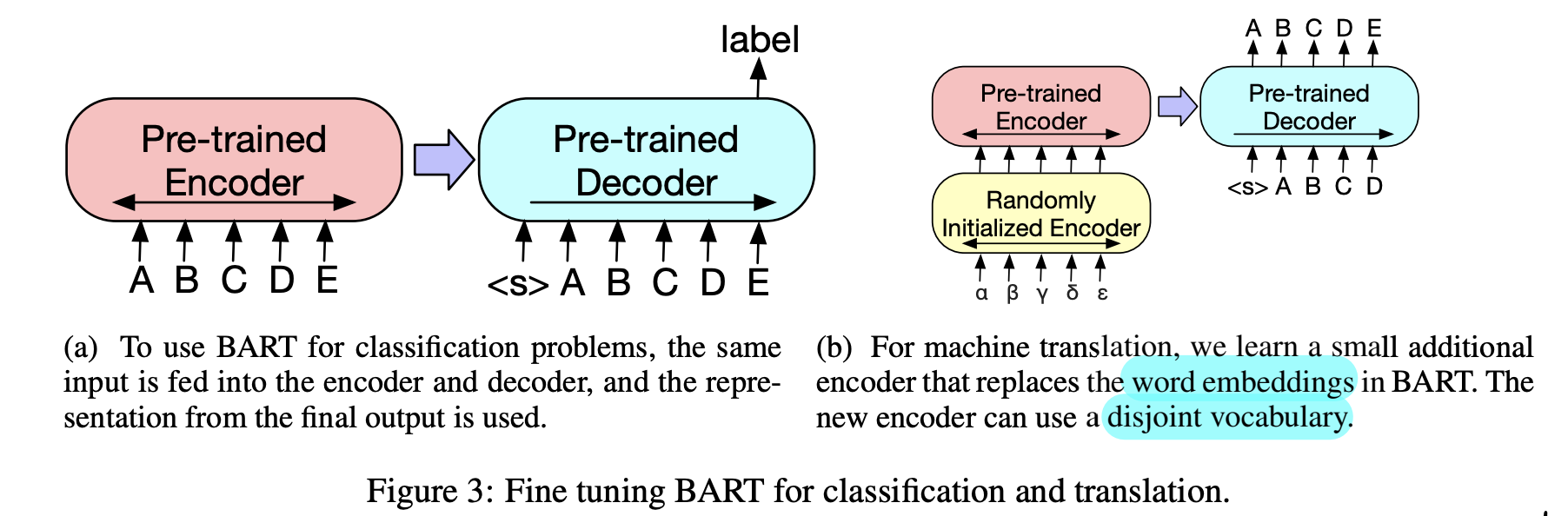
3.1 Sequence Classification Task
- decoder 의 last hidden state 에서 마지막 token 인 [END] 토큰의 representation 사용 (BERT 는 첫 token인 [CLS] 사용) → linear classifier 의 input
3.2 Token Classification Task
- last hidden states 사용 : 각 토큰별 representation 을 각각 분류를 위해 사용
3.3 Sequence Generation Task
- decoder를 포함하기에 그대로 fine-tune : abstractive QA, summarization
3.4 Machine Translation
- 선행연구(pre-trained encoder 활용) 와 달리 pre-trained decoder 을 함께 사용 시, 효과가 우수하다는 것 확인
- fine-tuning for MT
- random init 된 embedding layer을 encoder의 첫 layer로 추가한다.
- 해당 embedding layer와 positional encoding layer, 첫번째 input-attention projection 외에 BART의 params 을 freeze 한채로 학습한다
- 모든 모델의 parameter를 unfreeze 후 적은 수의 step 동안 학습한다
4. Comparing Pre-training Objectives
- base model(6 encoder, 6 decoder, 768 for hdim)을 사용
4.1 Comparison Objectives
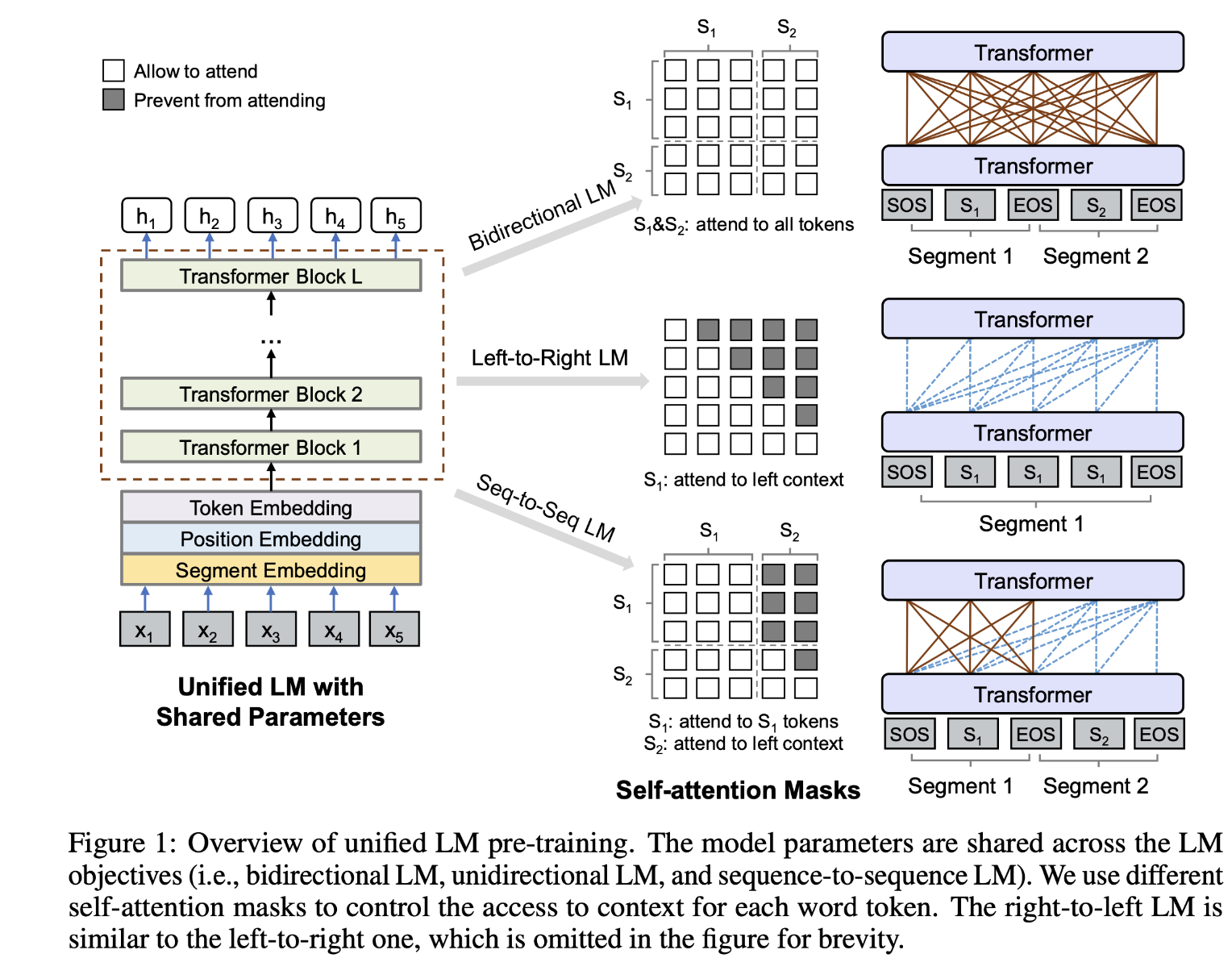
- Language Model : GPT 방식과 동일
- Permuted Language Model :
- 임의의 1/6 token 에 대해 permutation 으로 random order 구성
- Masked Language Model : BERT와 동일
- Multitask Masked Language Model : UniLM 기법과 동일
- 1/6 : left-to-right
- 1/6 : right-to-left
- 1/3 : unmasked
- 1/3 : first 50% unmasked + left-to-right mask
- Masked seq-to-seq : MASS
- 50% token의 span 을 마스킹
- 이를 예측하도록 학습
fine-tuning setting 실험
- 일반적 seq2seq 방식 (우세) : “input” → encoder, decoder → “target”
- src as prefix 방식 : “input” → encoder, decoder → “src + target”
4.2 Tasks
- SQuAD
- extractive QA
- input to encoder: [question; context]
- two classifier : start, end index
- MNLI
- bitext classsification
- input to encoder, decoder : [S1; S2; [EOS]]
- ELI5
- long-form abstractive QA
- input to encoder : [question; document]
- XSum
- news summarization (highly abstractive)
- ConvAI2
- dialogue response generation task
- input to encoder : [context_p1; context_p2; …]
- CNN/DM
- news summarization (relatively extractive)
4.3 Results
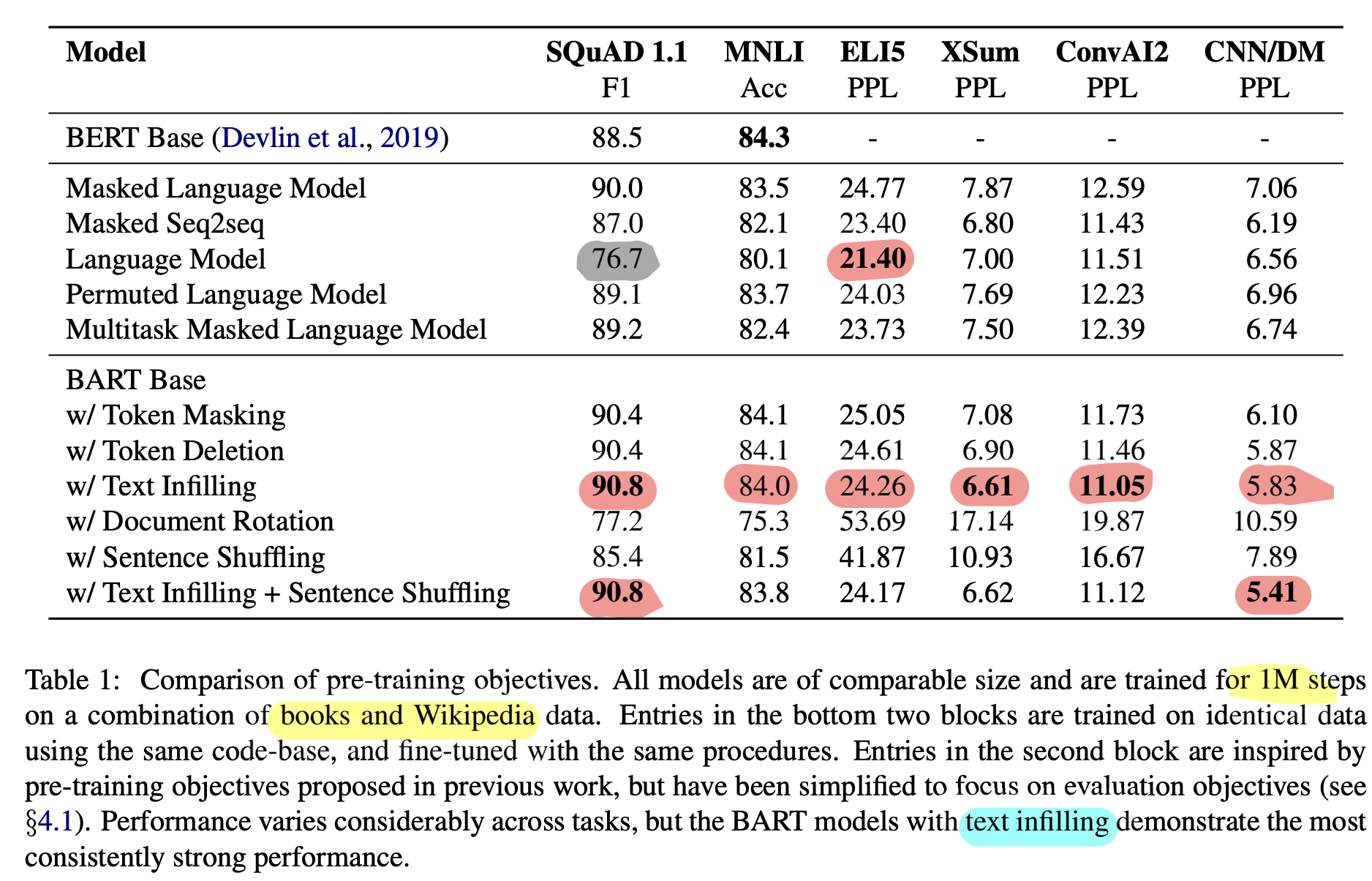
- pre-training 방식 성능은 task별로 상이했다
- 순서를 바꾸는 obj (permuting sentence, rotating docs)보다, masking 관련 기법(token deletion, masking, self-attention mask)들이 좋은 성능을 보였다
- Left-to-Right을 가지는 (autoregressive) pre-train 방식이 generation 에서 우세했다 (MLM이나 permuted LM 제외)
- 위와 반대로, SQuAD 에서는 사전학습에서 bidirectional 한 방식이 우세했다 (BART는 절반의 수만 사용)
- ELI5에서는 LM이 우세했다. 그러나 해당 데이터셋은 상대적으로 PPL이 낮아 일종의 outlier에 해당하는 데이터로 해석할 수 있다. (target이 input과 상대적으로 연관성이 낮은 데이터셋)
5. Large-scale Pre-training Experiments
- 비교를 위해, RoBERTa 와 같은 scale로 학습
5.1 Experimental Setup
- large-model : N = 12 (enc, dec 각각), hdim = 1024
- BS = 8k, 0.5M steps
- GPT2Tokenizer(BPE)
- text infiling(30%) + sentence permutation (sequence 내 모든 문장)
5.2 Discriminative Tasks
- RoBERTa와 비교
- 유사한 자원 사용, classification 성능을 잃지 않고도 더 좋은 generation 성능 달성

5.3 Generation Tasks
- label smoothed CELoss (smth = 0.1)
- beam = 5
- duplicated trigram 제거
- min-len, max-len, length penalty 튜닝 (val-set)
Summarization
- CNN/DailyMail (상대적으로 extractive) : BART 가 SOTA
- XSUM (매우 abstractive) : BART 가 SOTA (약 6.0 ROUGE)

Dialogue
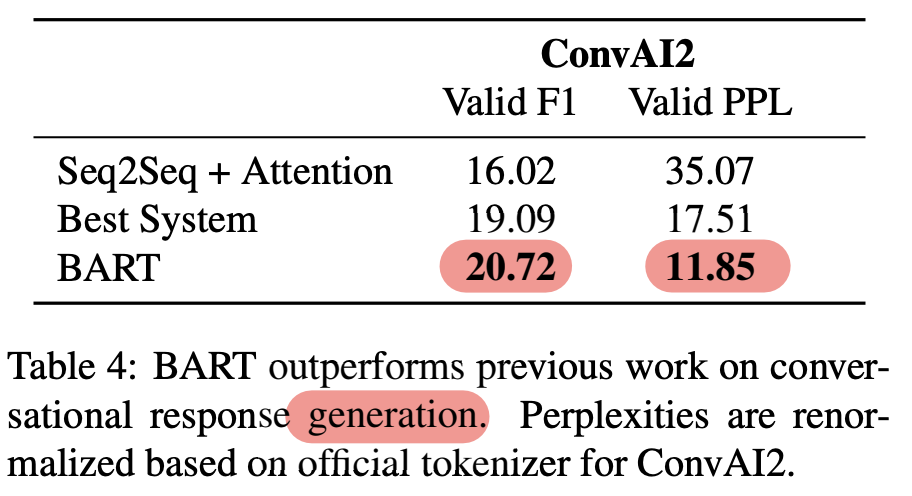
- ConvAI2
- BART SOTA
Abstractive QA
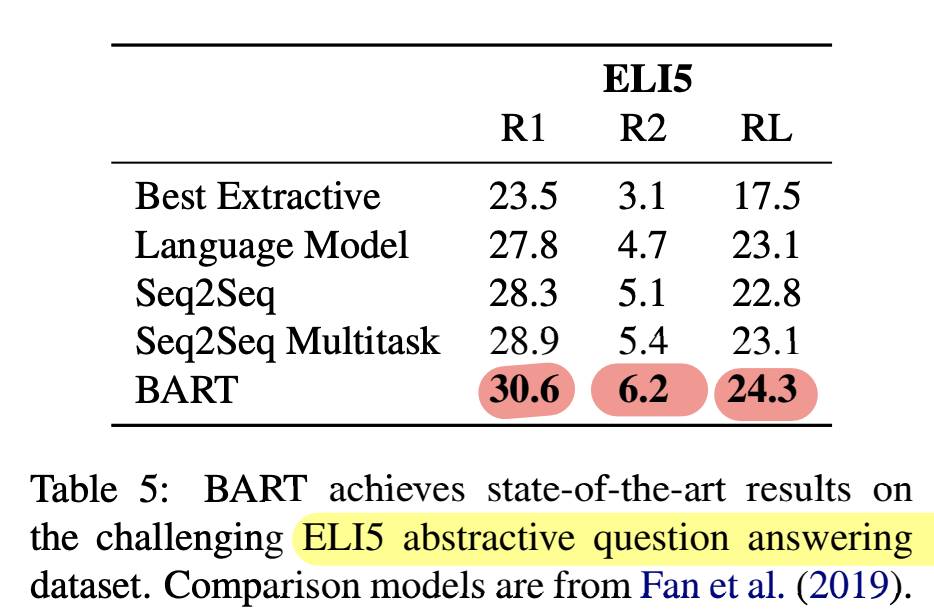
- ELI5
- BART가 1.2 ROUGE-L로 SOTA
5.4 Translation
- WMT16 Romanian-English
- 모든 실험 방식에 back-translation 기법 적용
- beam = 5, length_penalty (α = 1)

6. Qualitative Analysis
- Abstractive Summarization
- Dataset 구성 이후에 작성된 Wikinews 에 대해 summary generation
- 첫번째 문장 제거 (extractive 하지 않도록)
- fluent, grammatical, not extractive
- 사실과 다른 부분 일부 존재
- BART : 강한 NLU + NLG
7. Related Work
- Pre-trained Models : Language Models
- GPT, ELMo
- Pre-trained Models : Masked Language Models
- BERT : MLM 소개
- RoBERTa : 학습시간 증대
- ALBERT : parameter sharing
- spanBERT : span 사용
- UniLM : Ensemble of MLM
- UniLM : generation task에서 항상 autoregressive 하지 않기에, discrepancy 존재 (left-to-right 이외 기법을 사용하기 때문)
- BART에서는 이에 반해, 항상 left-to-right decoder 사용 : fine-tuning에서의 discrepancy 감소
- MASS
- span masked sequence, sequence of missing token 간에 mapping 관계 학습
- 두 언어 사이에 (번역) 공통적으로 존재하지 않는 단어(disjoint) 에 대해 학습할 수 없는데 반해, BART는 이를 해결했다
- XLNet
- permuted language modeling 사용
- generation에서 BART가 더 유사한 scheme 사용 (left-to-right)
8. Conclusions
- BART : corrupted docs → original
- discriminative task에서의 RoBERTa 와 유사한 성능 및 generative task에서의 SOTA 달성





댓글 영역